VISION: A Modular AI Assistant for Natural Human-Instrument Interaction at Scientific User Facilities
Citation
Mathur, S.; van der Vleuten, N.; Yager, K.G.; Tsai, E. "VISION: A Modular AI Assistant for Natural Human-Instrument Interaction at Scientific User Facilities"
Machine Learning Science and Technology 2025,
TBD.
doi: 10.1088/2632-2153/add9e4Summary
We describe the use of large language models (LLMs) as a natural-language interface for user control of complex scientific instruments.
Abstract
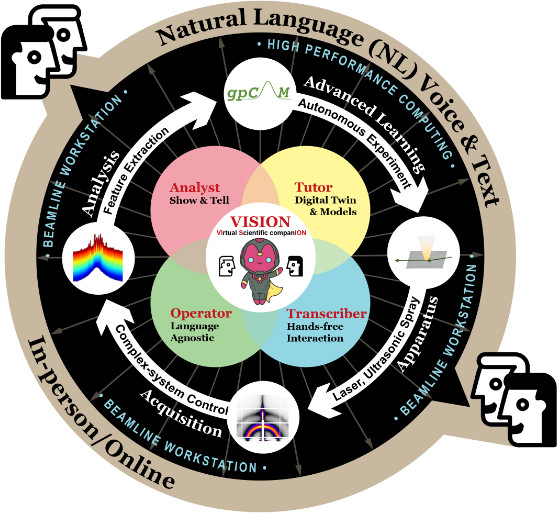
Scientific user facilities, such as synchrotron beamlines, are equipped with a wide array of hardware and software tools that require a codebase for human-computer-interaction. This often necessitates developers to be involved to establish connection between users/researchers and the complex instrumentation. The advent of generative AI presents an opportunity to bridge this knowledge gap, enabling seamless communication and efficient experimental workflows. Here we present a modular architecture for the Virtual Scientific Companion (VISION) by assembling multiple AI-enabled cognitive blocks that each scaffolds large language models (LLMs) for a specialized task. With VISION, we performed LLM-based operation on the beamline workstation with low latency and demonstrated the first voice-controlled experiment at an X-ray scattering beamline. The modular and scalable architecture allows for easy adaptation to new instruments and capabilities. Development on natural language-based scientific experimentation is a building block for an impending future where a science exocortex---a synthetic extension to the cognition of scientists---may radically transform scientific practice and discovery.
