Google announce Gemini for Science: Literature Insights (based on Notebook LM), Hypothesis Generation (built on Co-Scientist), and Computational Discovery (based on AlphaEvolve and ERA).
Alec Radford, David Duvenaud, and Nick Levinetrained a 13B LLM purely on pre-1930 text data. This model, Talkie, can be used to test ideas about knowledge vs. reasoning. As one example, this model, despite never seeing Python code, can (barely) do simple things with Python purely via in-context learning.
Anthropic reveal an as-yet-unreleased model, Mythos, with improved software abilities. This model has the ability to discover software vulnerabilities across a wide range of libraries; hence Anthropic delaying access. In the meantime, they launched Project Glasswing in an effort to secure global software infrastructure.
Meta releases (not open source) Muse Spark, multi-modal reasoning with agent orchestration.
Google show Fabula, an AI tool to help with writing stories.
OpenAI reveal ChatGPT Images 2.0. They claim it is a reasoning-based image model, able to create sets of images with coherence within image and across images.
Kimi (Moonshot AI) releases: Attention Residuals. They update the attention mechanism to attend over previous layers. This replaces the need for a residual stream, providing a cleaner approach to enable information passing through the depth of a deep architecture.
Tesla releases safety data. Driving with Full Self-Driving (Supervised) yields a lower collision rate than without (and especially when compared to the US driver average).
Existential Risk and Growth (by Philip Trammell and Leopold Aschenbrenner). Their model challenges the conventional wisdom that slowing down AI development reduces existential risks; they suggest in some cases it actually increases risks. (Similar to the overhang arguments.)
ARC-AGI-3 Toolkit released. The competition launches on March 25 2026, and the benchmark requires AIs to successfully solve video-game like tasks/puzzles.
Recursive Language Models. Treats context as a tool-use problem; the model can iteratively probe/query/search through the full context history to pull out relevant information into the current context window.
Pruning as a Game: Equilibrium-Driven Sparsification of Neural Networks. Trained networks can be significantly compressed; 90% reduction in size with minimal (<0.5%) decrease in performance. This approach improves over other pruning methods, by introducing the idea of parameters “competing” with each other for representation in the equilibrium pool.
A number of results advancing the state-of-the-art in LLM context handling and memory:
Recursive Language Models. Treats context as a tool-use problem; the model can iteratively probe/query/search through the full context history to pull out relevant information into the current context window.
Anthropic introducesCowork: Claude Code, applying the agentic Claude Code behavior to more general tasks. Initially only available on Mac OS to Max subscribers.
Google launches Universal Commerce Protocol (UCP) to standardize the way agents interact with commerce.
Peter Steinberger created clawdbot (a pun on “Claude Bot”); an AI Agent given broad autonomy over their human’s resources. The tool proved immediately incredibly powerful, addictive to use, and dangerous (from a computer security perspective).
Anthropic requested a name change; the project rebranded as moltbot, and then as OpenClaw.
A separate group then launched moltbook, a Reddit-like social media platform only for AI agents. Within a few days, >30,000 agents had signed up, forming sub-communities and discussing diverse topics. Another day and the registration was at 1.5M agents having generated 230,000 comments.
There are many unknowns (to what extent are viral examples of AI posting actually human nudges), and of course all the AI behaviors are downstream of being trained on Internet forum data and being prompted by their human owner to engage in the site. Nevertheless, there is reason enough to find this quite interesting.
Nvidia announces its next-generation AI platform: Rubin.
Razer Project Ava is a desktop object, powered by Grok, that displays an avatar and can help/coach/etc.
Robots
Boston Dynamics updates about their upgraded Atlas design. The robot has joints with large rotational freedom, allowing inverting the work direction quickly and easily.
1X updates on the 1X World Model that underlies their Neo robot, claiming improved self-learning. The system predicts task execution by essentially running a video model to predict future states and results of its actions.
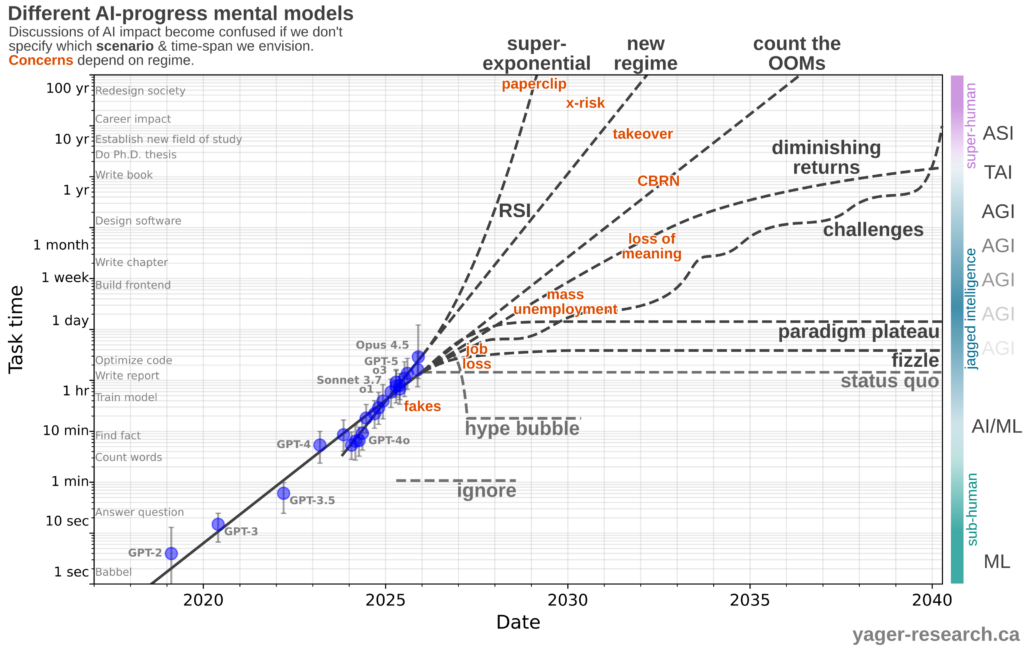
METR reports a record-setting time on their task length benchmark: Opus 4.5 reaches almost 5 hours (though sparsity in the available evaluations at this time horizon make data increasingly unrealiable).
From this, we can update our predictions. It appears that progress continues along the established exponential, with capabilities doubling every 4-5 months.
AI Agents
Google: Distributional AGI Safety. They argue that AGI may first arise as an emergent property of a collection of agents.
Google unveils Gemini 3 Flash; a very fast and very good (sometimes better than Gemini 3 Pro!) model.
AI Agents
Google DeepMind: Towards a Science of Scaling Agent Systems. If individual agent performance is too low, multi-agent systems tend to do even worse. Independent agents lead to error amplification, while central coordination can reduce this effect.
The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics. Scaffolding of LLM (including system-2 inspired coordination layer) demonstrates that many of the perceived problems (hallucination, limited capabilities, etc.) are not intrinsic limits of LLM cognition, but more resultant from deployment.
Gen 4.5 video model, improved model with native audio.
Edit audio of existing videos, and multi-shot editing.
GWM-1 (General World Model), allowing predictions of future states (e.g. for robotics). Three variants: GWM Worlds for explorable environments, GWM Avatars for conversational characters, and GWM Robotics for robotic manipulation.