They find that models learn reward hacking, and that this is entangled with other bad/undesired behaviors. Interestingly, by changing the RL system prompt to allow reward hacking, they were able to decouple this from other bad behaviors. They frame this as “inoculation prompting”; it stops generalization of bad behaviors to larger misalignment.
LLM
Anthropic unveilsClaude Opus 4.5. Beats Gemini 3 Pro on many (but not all) benchmarks, making it competitive with the state-of-the-art.
Modern image synthesis relies on inferring patterns at different length-scales or doing patchwise prediction. But why not do next-pixel prediction? Traditionally, this is considered too computationally expensive. Google now publish: Rethinking generative image pretraining: How far are we from scaling up next-pixel prediction? Their scaling suggests ~5 years until we reach this capability.
Solving a Million-Step LLM Task with Zero Errors. They break problems into the smallest possible units, and use multi-agent voting for each step. This decreases the per-step error rate low enough that long task sequences can be handled.
Shenzhen MindOn Robotics is testing their robot brain in the Unitree G1 body. If the claims are true that this motion is not teleoperated, it is indeed remarkably fluid and capable.
ElevenLabs releasesScribe v2 Realtime. Extremely fast and accurate realtime (150 ms) voice transcription. (And LiveCaptions for captioning live events or broadcasts.)
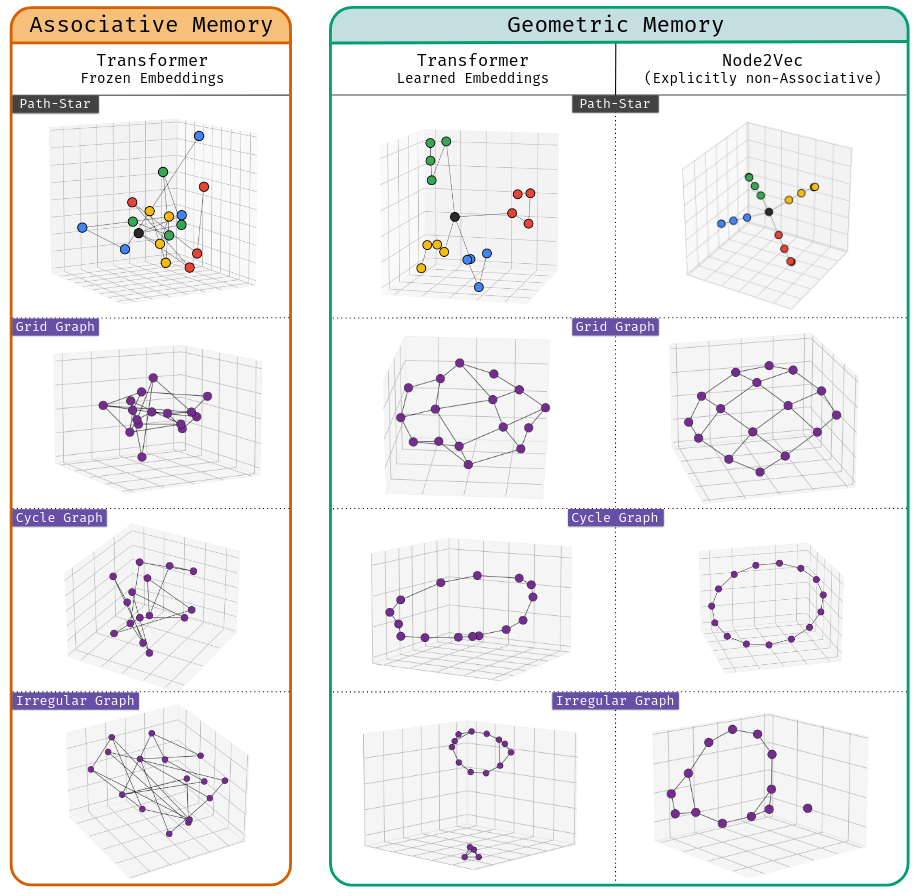
Continuous Autoregressive Language Models. Instead of generating one token at a time, it updates a semantic vector that can map to multiple output tokens. This provides a more continuous mode of “thinking”.
Less is More: Recursive Reasoning with Tiny Networks (blog). A small (7M) network is able to out-reason larger systems, exploiting two recursive networks. This small model is optimized to handle a certain class of puzzle; thus it cannot handle general tasks (or any language task) like an LLM. But the work demonstrates that a small iterative system can deploy remarkably strong “reasoning” effort.
Nvidia announce: RLP: Reinforcement as a Pretraining Objective (paper). They apply RL in the pre-training phase (instead of only post‑training), treating chain-of-thought as actions which can be rewarded by information gain.
OpenAI announceSora 2 (system card). More realistic, includes sound, ability to add a specific person to a scene, multiple aesthetics. The app is iOS only (for now) and emphasizes social aspects (friend invites, etc.).