A stealth/mystery model is being tested: nano-banana (speculation is that it is from Google). Early examples show it has startling ability to edit images based on natural language requests.
Video
Higgsfield product-to-video demonstrates ability to add objects into existing footage. This shows the increasingly powerful modality of genAI video editing.
Runway Act-Two updates to include changing voice performance alongside video generation.
World Synthesis
Runway ML announcesGame Worlds. Turn-based text-adventure games with generated narrative and images.
New Anthropic research: Persona vectors: Monitoring and controlling character traits in language models. Many interesting results, including inducing a particular behavior by adjusting activations in a particular direction. Used at inference-time, this can induce or inhibit behavior, but at a cost in capability (as previously known). E.g. one can steer away from the “evil” direction, but one worsens model task performance. But interestingly, one can steer the model during training to prevent certain behaviors from ever being learned. Counter-intuitively, one actually steers towards an undesired behavior (e.g. in the evil direction) during training. This acts as a sort of inoculation, since the model doesn’t need to add the over-emphasized behavior to its learned weights; and at runtime (when the bias is no longer present) it snaps back to desired behavior (e.g. towards the good direction).
OpenAI announces the release of two open-weight reasoning models: gpt-oss-120b (for servers or high-end desktops) and gpt-oss-20b (for desktop/laptop). Local reasoning model (full access to chain-of-thought) that should be good for agentics (hf, github, test). Supposedly similar in capability to o4-mini.
Reasoning model that selects the right amount of compute. Multiple models behind the scenes: GPT5 (default), GPT5-mini, GPT5-nano, GPT5-Pro (for Pro tier only). Available in API.
It’s better. Strong performance across many metrics: 75% on SWE-bench, 84% MMMU, 100% AIME 2025. Better writing, better coding. Improved voice. Can see via video input.
Can now select among different “personalities”.
Trained (in part) by using o3 to generate teaching datasets.
Google paper provides insight into how LLMs can do in-context adaptation: Learning without training: The implicit dynamics of in-context learning. They find that the transformer architecture leads to each token generating a “temporary patch” that steers the model, as if it were fine-tuned on the context data.
New paper with a bold claim: AlphaGo Moment for Model Architecture Discovery. They claim that searches through different AI/Ml architectures can consistently yield discoveries/improvements, including surprises humans might not have considered.
LLM
Google NotebookLM rolls out a new user interface, and adds video overviews.
Memories.aiintroduces a Large Visual Memory Model. The claim is that it enables reasoning over video with nearly unlimited context length. This is accomplished by generating concise semantic codes for each frame, allowing search over long videos.
Hunyuan announceHunyuan3D World Model 1.0 (github, huggingface). Currently supports movement within a small circle from the initial viewpoint. But helps point the way towards more general-purpose sims.
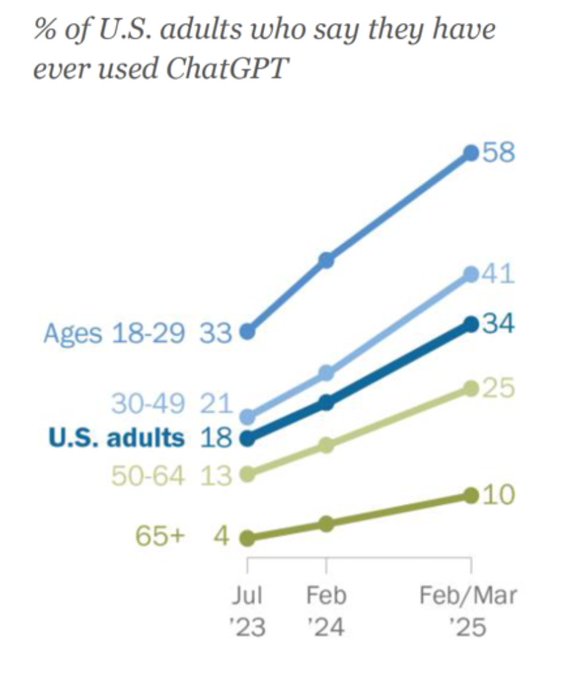
In general, tech adoption is faster now than in the past. AI adoption is even faster than the modern typical trend
There are interesting parallels between human psychology and AI responses. New research: Call Me A Jerk: Persuading AI to Comply with Objectionable Requests. Shows that LLMs can be persuaded using methods similar to humans. This doesn’t mean LLM internal cognition is humanlike, but at least shows how LLMs are reproducing (modeling) human foibles.
Learning from one and only one shot. A new “information lattice learning” approach shows good generalization (better than transformer, for certain visual tasks).
OpenAI goldwas done with an LLM not using tools (theorem prover, etc.). It was a special unreleased LLM; but it was not optimized on math problems per se, but rather implementing some new kind of improved algorithm (presumably RL?). This level of capability is expected to be included in a future OpenAI model (but not GPT-5).
There is also a claim of using o4-mini-high to achieve IMO gold (using the Crux agent framework).
Taken together, these results suggest that reasoning models are already at a very high level of math competence. Moreover, it adds some evidence that existing LLMs have many latent skills, that RL can unlock.
METR analysis: Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity (blog, commentary/analysis). Their results show that use of AI tools by programmers decreased productivity. This is surprising to the large number of programmers who use LLMs to improve their work. One caveat is that this was analyzing productivity gains for developers working on their own codebases (whereas the biggest gains for LLM usage comes from exploring unfamiliar topics/code). One might also wonder how the results change for free-form use instead of as prescribed in this study. Nevertheless, this does weaken the argument for AI already delivering productivity gains.
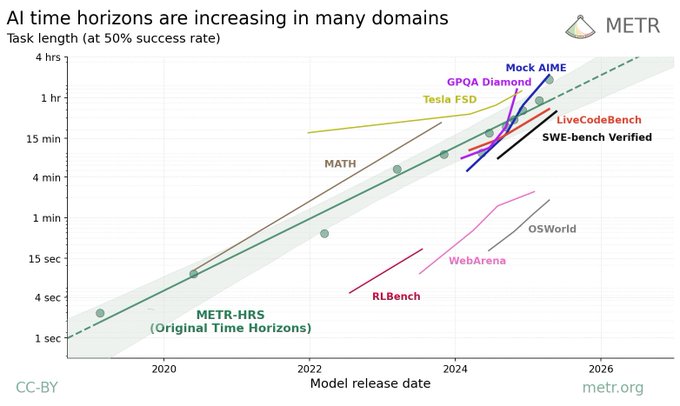
METR is showing results for a wider range of tasks (this appears to be an update to their earlier report from May 2025). The landmark METR result showed that AI execution of software engineering tasks (as measured by “task time” for a human to complete) was increasing exponentially. Now they add a variety of other tasks to the evaluation. Each tasks shows some form of exponential scaling, though the magnitude and scaling differ.
It is worth remembering that there will be tradeoffs between performance and monitorability. Various “thinking in latent space” approaches have demonstrated improved performance, but that obfuscates AI thinking (requiring imperfect mechanistic interpretability to then attempt to recover internal processes). We should be willing to give up some immediate performance gains in order to increase our ability to align (which will yield more long-term gains).
LLM
Kimi AIreleasesKimi-K2, an open-source (permissive license) 1T parameter model (MoE, 32B active). It performs extremely well across multiple benchmarks, especially coding, despite being a non-reasoning model (try it, API, code, weights).
OpenAI launches Agents (video). It uses a combination of text-browsing agentics (like Deep Research) and visual-browsing (like Operator) to handle open-ended asynchronous tasks. It can access connectors (Google Drive, etc.), tools (image generation), and can generate (e.g.) slide decks. Achieves 42% on Humanity’s Last Exam and 27% on FrontierMath.
Runway is starting to deploy Act-Two, an improved motion capture model that can transfer a video performance to an AI avatar based on a single input image.
Predicting thinking time in Reasoning models. By predicting estimate token needs during CoT reasoning, feedback to user (e.g. progress bar) could be provided. Models internally have state that is predictive of further token usage.
gremllm is clever and/or diabolical. It is a Python library that generates on-the-fly the attributes and methods of a Python object. Thus, one need not actually define the methods for a new class; simply allow the LLM to hallucinate them when they are called for.
Although this sounds silly and dangerous, there are viable use-cases. In March 2023 (site and code no longer online), there was some exploration of “imaginary programming” wherein one would define a function’s requirements but never actually code the function (the LLM would instead stand-in for the function at call time).
xAI release Grok 4 (and Grok 4 Heavy). Benchmarks are strong, taking the lead on several, including 100% on AIME, 44% on Humanity’s Last Exam, and 16% on ARC-AGI-2 (c.f. 9% Claude Opus 4). If real-world utility matches benchmarks, then Grok 4 may take the lead as the best model.