Research Insights
- Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data. Surprising result: Training LLM on (x,y) pairs enables it to infer the underlying function (define it in code, invert it, compose it). Reasoning is occurring non-transparently in weights/activations.
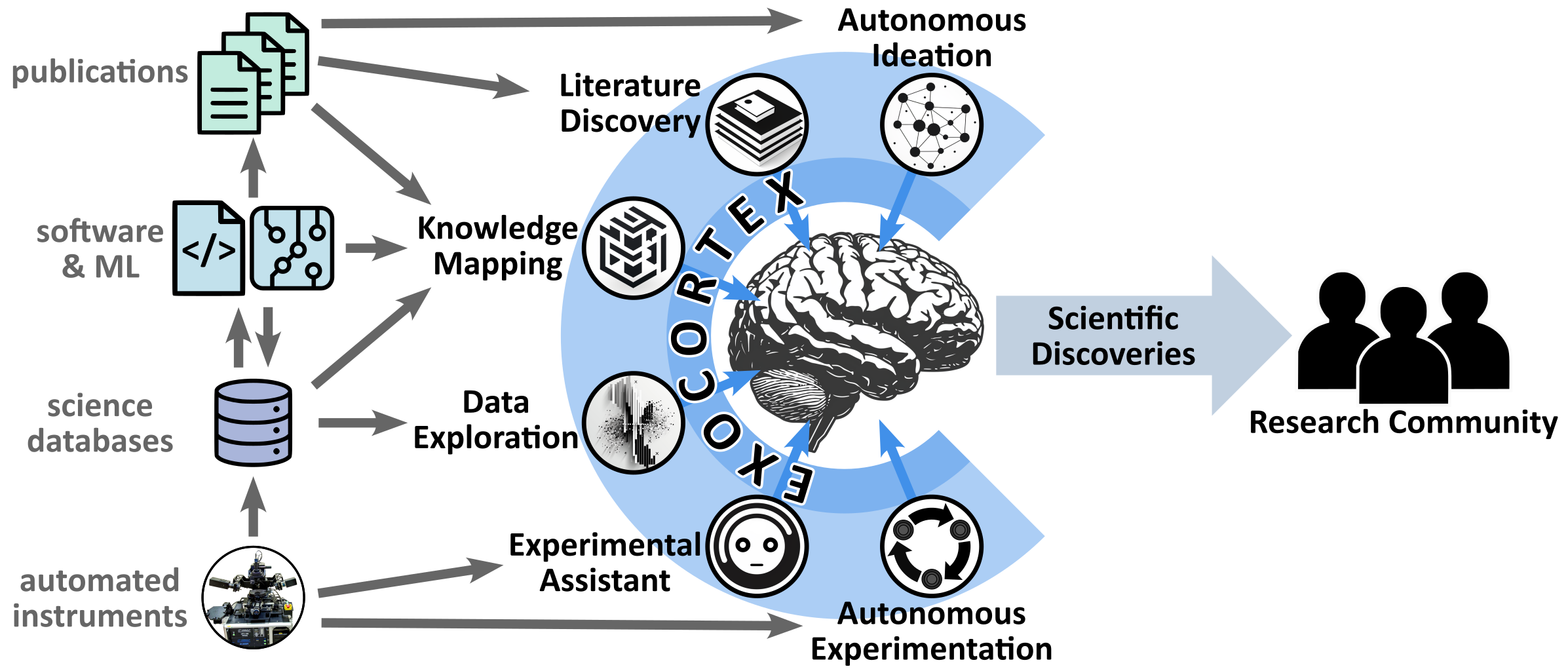
- I posted a preprint of an idea for a “science exocortex”. Essentially, a swarm of AI agents working together on tasks, and picking only high-value ideas and decisions that require human consideration. It’s just a set of ideas for now.
Anthropic
- Anthropic released Claude 3.5 Sonnet. It is better than the larger Claude 3 Opus, and beats GPT-4o on many evals. (So presumably 3.5 Opus will be very smart?) It also has “artifacts”, which are sidebar visualizations/interactions that it can update and modify based on your requests. Interestingly, it seems to use special <antThinking> tags so that it can do chain-of-thought but have that output hidden from the user.
OpenAI
- OpenAI acquired Rockset, a database/analytics company. The intended use seems to be for customers (especially corporate) to integrate data retrieval into LLM products.
- Multi is a MacOS app for slick collaborative screenshare. They are shutting down their offering and instead “joining” OpenAI (merging with? being acquired by?). Some are guessing this means OpenAI will launch a radically new kind of operating system, where AI agents are first-class components. I think the simpler prediction is that they want their AI agent to “screenshare” by being able to see what’s on your screen and point at things, or even edit things or click buttons (with your permission). That would be useful.
- Announced a partnership with TIME. Could either represent training data, or integration of sourced results in future ChatGPT replies (probably both). This is on top of other partnerships they’ve announced: Financial Times, Stack Overflow, Reddit, News Corp, Vox Media, The Atlantic, Apple.
- Taken together, these make it seem like OpenAI are putting more focus on delivering a compelling consumer product.
- On the research side, OpenAI put out a preprint showing how an LLM can be trained to critique another LLM. The critic can catch errors in the code output of ChatGPT. Small step towards iteration loops to improve outputs.
LLMs
- Nvidia releases Nemotron-4 340B models and training dataset.
- Google opens developer access to Gemini 1.5 Pro with 2M context window. That’s a lot of context.
Science
- AlphaFold is already having a sizable impact on protein structure determination. Now, startup EvolutionaryScale has announced ambitions to enable programmable biology. Their preprint is equally ambitious: Simulating 500 million years of evolution with a language model. (See also prior publication cred.) They have open-sourced their ESM3 foundation model, which is trained on sequence, structure, and function of proteins. So you can (e.g.) input a desired function and it will generate a candidate protein. If these claims pan out, this could accelerate bio/medical research.
- Some new work has demonstrated an RNA method for gene editing. In terms of utility, this is similar to CRISPR; in fact it could provide some capabilities beyond what CRISPR can do. Combined with more and more AI-based bio-design, this could lead to some interesting developments.
Robots
- Kinda novel approach to AI/control for robotics: Dreamitate involves having the AI ‘dream’ an upcoming action (i.e. predict what the required action would look like in its camera vision), and then imitate that set of actions. The advantage here is that this leverages the power of generative video. You train a model on a bunch of video, so that it can correctly predict the next frame. Then that’s what you use for robot control. (This is the sense in which OpenAI claim Sora is a world-simulator and hence can be used to understand and act.)
- A related robot-control effort: Embodied Instruction Following in Unknown Environments. Multi-modal model for robot following commands. Language model to understand human request. Builds a high-level plan and steps within it. Explores environment if necessary to learn more. Leveraging LLM means it can handle arbitrary tasks that it wasn’t specifically trained on.
Vision
- Supervision is a generic (and open-source) vision system. Seems to work very well for semantic video tracking.
- Microsoft open-sourced Florence-2, a lightweight vision-language foundation model useful for captioning, object detection, grounding, and segmentation. Interestingly, they created their training dataset by taking existing data and existing specialized models to create a unified set of well-labelled images. So this is another example of AI generating improved training data for AI.
Virtual Avatars
- C.f. prior progress.
- Synthesia is making avatars better; now the avatars can do realistic hand gestures timed to speech.
Tools
- One idea for easily creating AI workflows is to use spreadsheet-like interfaces, where cells can invoke AI/LLM/etc. in order to run tasks across a whole bunch of data. V7 Go and Otto are offering this.
Hardware
- Groq transitioned to being an AI cloud compute provider, instead of trying to sell people their custom chips directly. Their pricing on many models (including Whisper Large V3) are very good. They clearly have something to offer.
- Etched raises $125M for their specialized chips.
- Preprint recasts LLMs in a way that avoids matrix multiplication. Some are claiming this means the end of GPUs and Nvidia; that seems unlikely to me since there are so many current (and future!) data/ML/AI tasks that benefit from GPU/CUDA. But it is an interesting reminder that we don’t know what the optimal software architecture will be, thus it’s hard to know what the right hardware will be.