Opinions
- This interview with Andrej Karpathy is (no surprise) interesting. He shares his thoughts about the future of self-driving cars, robots, and LLMs. He talks about the future involving swarms of AI agents operating on behalf of the human. (Very aligned with my vision for each person having an exocortex; in fact they use the term exocortex in the discussion and reference Charles Stross’ Accelerando.)
- Aidan McLaughlin writes about: The Zero-Day Flaw in AI Companies. He exposes a fundamental tension between general AI companies (training ever-bigger models that can handle an ever-broader range of tasks) and narrow AI companies (who build wrappers/experiences on top of models).
- The narrow companies are nimble and can rapidly swap-out their underlying model for whatever is currently best. Yet, the big/general companies will eventually release a model so capable that the narrow use-case is fully subsumed. But they are cursed with competing with the other big labs, spending large amounts of money on models that will be forgotten as soon as someone else releases a better one.
- In this sense, both the general and narrow AI labs are “doomed”.
- Big/general labs lack the optionality of the narrow/wrapper companies. The big labs must (effectively) use their giant model to build any downstream product, even if that ties them into a worse model.
- As models get better, they are more sample efficient (they need less fine-tuning or instructing to handle tasks). This progressively decreases the value of “owning” the model (e.g. having the model weights and thus being able to fine-tune).
- This suggests that the “wrappers” ultimately have the advantage; in the sense that just one or two “big model providers” might prevail, while a plethora of smaller efforts built on top of models could thrive.
- Of course, consumers benefit enormously from rapidly increasing foundational and wrapper capabilities. The split between model-builders and wrapper-builders is arguably good for the ecosystem.
Research Insights
- Self-evolving Agents with reflective and memory-augmented abilities. Describes an agent with iteration/self-reflection abilities that exploits memory to alter sate. They propose a memory where a forgetting curve is intentionally applied to optimize memory.
- SciAgents: Automating scientific discovery through multi-agent intelligent graph reasoning (code). The system automatically explores scientific hypotheses and links between concepts.
- Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving. By exploiting meta-cognition (where the AI roughly thinks about thinking) and collaboration between AIs, performance can increase. In the demonstrated setup, one LLM labels math problems by the skills needed to solve them. Other LLMs then perform better at solving the problems with the skill labels. This cooperation thus increases performance on math problems; and may generalize to other knowledge domains.
- At some level, this sounds like “just” fancier chain-of-thought. I.e. you allow the LLM to first develop a plan for solving a problem, and then actually execute the solution. But this paper also adds some concreteness in this general approach.
- LLMs are sometimes accused of being uncreative (merely mix-and-match on existing things). So, it is worth rigorously testing creativity of LLMs.
- Some past work:
- 2023-Sept: “Best humans still outperform artificial intelligence in a creative divergent thinking task”. AI out-performed the average person, though the top humans were rated more creative.
- 2024-Feb: “The current state of artificial intelligence generative language models is more creative than humans on divergent thinking tasks”. AIs were found more original and elaborate.
- 2024-Jul: “Pron vs Prompt: Can Large Language Models already Challenge a World-Class Fiction Author at Creative Text Writing?”. GPT-4 writing was ranked lower than a selected top human author.
- Now: “Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers”. AI-generated original research ideas are judged more creative than human. (Idea feasibility was also assessed; AI ideas were judged slightly less feasible, but the difference is small compared to the relevant error bars.)
- Mo Gawdat makes a further claim that creativity is essentially algorithmic: “Creativity is algorithmic. Creativity is: here is a problem, find every solution to the problem, discard every solution that’s been done before. The rest is creative.”
- Overall this bodes well for the obvious near-term application: use the LLM to augment human creativity. By brainstorming/ideating with an AI, you can leverage the best of both worlds: better creativity, with human-level discrimination on the final ideas.
- Another paper offers a counter-point: Theory Is All You Need: AI, Human Cognition, and Causal Reasoning.
- They argue that AIs are data-driven as so inherently backward-looking, able to generate restricted kinds of novelty; whereas human thinking is theory-driven and so able to extrapolate to meaningfully different things in the future.
- This case might be over-stating things (humans are also mostly prone to naive extrapolative prediction; LLMs do create some kind of rough causal world model). But, it is true that humans are still smarter than AIs (do better at “considered/deliberative creativity” tasks) and so this framing might point towards how to improve AI intelligence (which is to add more theory-based predictive creativity).
- They also point out how belief mismatch (asymmetry) with the real world is good for creativity. Purely adhering to existing data can get one stuck in a local minimum. Whereas creative humans often express new ideas that are (at first glance) incorrect “delusions” about the world (not really matching existing data); but some of these contrarian ideas turn out to be correct upon further inspection/testing. (Most notably true for major scientific breakthroughs.)
- Interestingly, one can view this as a society-scale effect. Most people adhere closely to existing thought-norms. A minority deviate from these. Most of that minority do not contribute useful new ideas. But some new good ideas do arise, and their success makes them propagate and become crystallized as the new dogma. Similarly for AI, we could imagine intentionally increasing diversity (hallucinations) and rely on search to winnow down to successful new ideas.
- They point out how human learning is theory/science based: our minds make predictions, and then we operate in the world to test those predictions.
- Correspondingly, for improved AI, we would need to add predictive modeling, ability to test these theories, and deliberative reasoning updates on those. (Of course AI/ML researchers have thought about this: RL, agents, etc.) AIs need to be more opinionated, espousing semi-contrarian theories for the world, and suggesting concrete actions based on those theories.
- Some past work:
- Thermodynamics-inspired explanations of artificial intelligence. They define an “interpretation entropy” in formulation of AI, allowing them to optimize for responses that are more interpretable to humans. This thermodynamic analogy is an interesting way to improve AI control/safety.
- Self-Harmonized Chain of Thought (code). They develop a method for the LLM to produce a set of useful chain-of-thought style solutions for diverse problems. Given a large set of problems/questions, they are first aggregated semantically, then one applies the usual zero-shot chain-of-thought approach to solving each problem. But, then, one can cross-pollinate between proposed solutions to similar problems, looking for refined and generalize solutions. Seems like a clever way to improve performance on a related (but diverse) problems.
- Planning In Natural Language Improves LLM Search For Code Generation. The method generates a wide range of plans (in natural language) to solve a coding problem, and searches over the plans first, before transforming candidate plans into code. This initial search over plans improves final code output (in terms of diversity and performance).
- FutureHouse present PaperQA2: Language Models Achieve Superhuman Synthesis of Scientific Knowledge (𝕏 post, code). The system automated literature review tasks (authors claim it exceeds human performance), by searching (with iterative refinement), summarizing, and generating sourced digests.
LLM
Models:
- Last week saw the release of Reflection-Llama-3.170B, a fine-tune of Llama employing reflection-tuning to “bake in” self-corrective chain-of-thought. Reactions since then were mixed, then confused, and then accusatory.
- First, an independent analysis claimed worse performance than the underlying Llama (i.e. not replicating the claims).
- Then the independents were able to partially replicate the release benchmark claims, but only when using a developer-provided endpoint (i.e. without access to the actual weights).
- Additional reports surfaced claiming that the original developers were intentionally misleading (including some evidence that the provided endpoint was actually calling Sonnet 3.5, not Reflection).
- After many days of defending their approach (and offering suggestions for why things were not working), the developers finally conceded that something is amiss. They say they are investigating.
- The approach seems conceptually interesting. But this implementation has not lived up to the initial claims.
- DeepSeek 2.5 release: a 238B mixture-of-experts model (160 experts, 16B active parameters).
- Google released some new Gemma models, optimized for retrieval (which reduces hallucinations): RAG Gemma 27B and RIG Gemma 27B. Fine-tuning allows the model to have improved RAG and tool-use.
- It is known that AI labs use LMSYS Arena to covertly test upcoming model releases.
- In April 2024, gpt2-chatbot, im-a-good-gpt2-chatbot, and im-also-a-good-gpt2-chatbot appeared in the arena; later it was confirmed that these were OpenAI tests of GPT-4o.
- Now, we have the-real-chatbot-v1 and the-real-chatbot-v2 showing up. Some report that these bots take a while to respond (as if searching/iterating/reflecting). So, this could be a test of some upcoming model that exploits Q*/Strawberry (Orion?).
Multi-modal:
- Mistral releases Pixtral 12B, a vision-language model.
- Release of Llama-3.1-8B-Omni (Apache license, code), enabling end-to-end speech.
Evaluation:
- HuggingFace has released an evaluation suite that they use internally for LLMs: LightEval.
- Artificial Analysis has released a detailed comparison of chatbots. The results are:
- Best Overall: ChatGPT Plus
- Best Free: ChatGPT Free
- Best for Images: Poe Pro
- Best for Coding: Claude Pro
- Best for Long Context: Claude Pro
- Best for Data: ChatGPT Pro
Tools for LLMs:
- William Guss (formerly at OpenAI) announced ell (code, docs), a Python framework for calling LLMs that is simpler and more elegant than other options (e.g. LangChain).
LLMs as tools:
- It is interesting to see how LLMs are altering coding. In just a couple years, we’ve gone through several mini-paradigms:
- Traditional human coding (manually using tools like github, etc.)
- LLM-assisted, where one chats and copy-pastes code into the project.
- Copilot and Cursor paradigm, where LLM is integrated into IDE, providing code completions, in-context diffs, etc.
- Replit style, where the AI system also manages the dev environment (databases, deployment to cloud, etc.) in addition to writing code. The human iterates until the app is suitable. (You can even just give it partial code and have it intuit the required dependencies, environment, etc.)
- On the horizon are fully-automated AI agent software engineers (as promised by Devin). The performance of AIs on SWE-bench keeps increasing (Devin 14%, Amazon Q 20%, Honeycomb 22%). Here is a survey of the current state.
- Vercel v0 is a chat-based genAI for web development. Supposedly this entire video game was made using it. It’s simple and primitive (one level, basic graphics) but shows the potential of such systems.
- FutureHouse release: Has Anyone, an LLM-based literature search, providing sourcing for whether a topic has been studied.
- Dan Hendrycks et al. have released an AI-based forecasting platform (called FiveThiryNine). It uses GPT-4o to consider news items and weight various arguments to come up with an estimate. The accompanying blog post describes how they used historic crowd-average prediction market data to gauge performance, finding that it slightly exceeds the crowd-average (which is essentially already superhuman, since the wisdom of the crowd tends to outperform individual human estimates). An impressive result, if it pans out. This platform certainly seems useful to, for instance, get a rough gauge of claims for domains in which one is not an expert.
- Some are already questioning the methodology; others claim that replication attempts are failing. You can run your own test by asking the same question repeatedly, wherein predictions can easily vary ±10% (which provides some hint of how precise/variable results are).
- Relevant prior work:
- 2023-Oct: Large Language Model Prediction Capabilities: Evidence from a Real-World Forecasting Tournament.
- 2024-Feb: AI-Augmented Predictions: LLM Assistants Improve Human Forecasting Accuracy.
- 2024-Feb: Approaching Human-Level Forecasting with Language Models.
- 2024-Feb: Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy.
Image Synthesis
- Reshot AI are developing tools that allow one to precisely dial in image features (e.g. eye position and facial expressions). Image synthesis tools continue becoming more refined.
Video
- A new video generator system, roughly on par with other existing offerings: Hotshot (example outputs).
- Adobe announced the release of their Firefly video model (example outputs).
- Current batch of rather-good AI video generations:
Audio
- FluxMusic is an open-source rectified-flow transformer for music generation.
- Fish Speech 1.4 is a new open-weights text-to-speech (TTS) system that is multi-lingual and can clone voices (video, demo, weights).
- Read Their Lips. Estimates text transcription from video of speaking.
- I wonder whether combining audio transcription and visual lip-reading could improve performance.
- There are of course societal implications. While lip-reading has always been possible, being able to automate it makes it much easier to correspondingly automate various nefarious mass-surveillance schemes.
Brain
- Brain-computer interfaces (BCI) are envisioned in the near-term to mitigate disabilities (e.g. paralysis); but in the long-term to provide deeper connection between human minds and digital systems. However, this preprint throws some water on such ideas: The Unbearable Slowness of Being.
- They note the stark difference between the raw data-rate of human senses (gigabits/second) and human thinking/behavior (~10 bits/second). Human output (typing, speaking) is quite low-bandwidth; but even hypothetically directly accessing an inner monologue does not substantially increase the data-rate.
- Although the raw inputs to human perception are high-date-rate, the semantic perception also appears to be capped in the vicinity of ~10 bits/second. Similarly, the human brain neural network has an enormous space of possible states, and thus possible mental representations. But the actual range of differentiable perceptual states is evidently much, much smaller.
- Of course, one could argue that the final output (e.g. through fingers) or even the internal monologue, are constrained to a certain sensible throughput (coarsed-grained to match reality of human experience); but that our underlying mental processes are much richer and thus have higher data-rates (that hypothetical BCI could tap into). The paper goes through these arguments, and presents several lines of evidence suggesting that even many mental inner representations are also operating at a similar ~10 bits/s rate.
- The authors do note that there is likely something missing in current understanding, that would help to explain the true representational complexity of the brain’s inner work.
- Thus (in a naive interpretation), future BCI in some sense have constrained utility, as they can only slightly improve over existing data-output-rates. Even for those with disabilities, the implication is that far simpler interfaces (e.g. just voice) will achieve similar levels of capability/responsiveness.
Hardware
- The 01 Light (gadget for voice interface to computer) is being discontinued. The company is switching to provide an app experience.
- TSMC’s new facility in Arizona is on-track; already achieving yields on par with other fabs. It appears on schedule for full production in 2025.
- Groq has demonstrated further speed improvements for LLM inference, through software tweaks on top of their custom hardware. E.g. >500 tokens/s for Llama 3.1 70B.
Cars
- 2023 safety analysis of Waymo self-driving vehicles found that they generate fewer accidents than human drivers (after accounting for things like reporting biases). Digging into the details, it turns out that Waymo vehicles get into fewer accidents, but also those accidents they have are overwhelming attributable to the other vehicle (human driver). At least within the regimes where Waymo cars currently operate, it would thus save human lives to transition even more vehicles to Waymo self-driving.
Robots
- Last week, 1X released some videos of their Neo humanoid robot. S3 have interviewed 1X, and they demo a video of Neo doing some simple tasks in the interviewer’s apartment. 1X describes a strategy wherein robots will initially be teleoperated for difficult tasks, and AI-controlled for simpler tasks. Over time, the fraction of AI control is meant to increase to 100%. A sensible strategy; with obvious privacy concerns. The actions in the videos were apparently all tele-operation.
- Apparently the battery is just 500 Wh (much less than Optimus or Figure), allowing the robot to be quite light. They say that they compensate by using more energy-efficient actuation (95% efficient, vs. ~30% for geared systems).
- Pollen Robotics are aiming for tele-operable humanoids built using open source tools. This video shows their Reachy 2 (Beta) prototype.
- A video of Unitree G1 degrees-of-freedom.
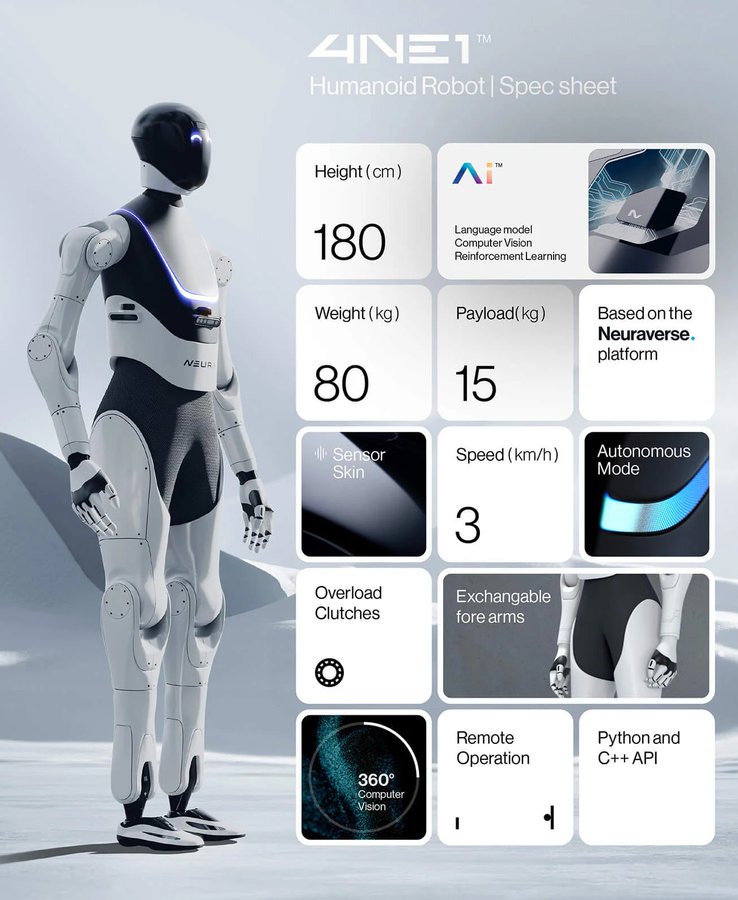
- Promotional video of NEURA’s 4NE-1 robot performing some tasks (another one).