
General
- Google releases an essay on the potential of AI for science: A new golden age of discovery: Seizing the AI for Science opportunity. In addition to outlining an optimistic future (not dissimilar from Dario Amodei’s Machines of Loving Grace), it provides practical insight about what problems are best attacked using modern AI.
- Aidan McLaughlin essay: The Problem with Reasoners. He notes three trends that suggest AI will progress more slowly that suggested by naive/optimistic scaling arguments:
- It was hoped that multi-modal models (ChatGPT 4o, voice+text models, etc.) would exhibit significant capability improvement from transfer learning across modalities. This has not borne out.
- Iterative/reasoning models (OpenAI o1, DeepSeek r1, etc.) show that using RL can yield gains in narrow domains with clear metrics (contrived math problems), but we are not seeing evidence of this leading to generalized improvements in intelligence (in areas without easy verification).
- No large model (larger than GPT4 or Claude 3 Opus) have been released, suggesting major challenges there.
- Attitudes and perceptions of medical researchers towards the use of artificial intelligence chatbots in the scientific process: an international cross-sectional survey (Nature commentary: Quest for AI literacy). Overall, the study finds substantial interest in AI chatbots among researchers, but also a lack of understanding of these systems.
Research Insights
- Replication of “o1-style” chain-of-thought reasoning is heating up:
- Last week saw announcement of DeepSeek-R1-Lite-Preview.
- Update from Walnut Plan’s attempt to replicate o1 (c.f. part 1, code): O1 Replication Journey — Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?
- Paper from Alibaba: Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions.
- Alibaba Qwen releases: Qwen QwQ 32B (weights, demo). This appears to be a separate implementation of the “o1-style” reasoning chain-of-thought approach.
- Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models. There is always debate about whether LLMs “truly reason” or “simply memorize”. This paper proposes that reasoning is based on extracting procedures from training data, rather than simply memorizing outputs. So it is a matter of finding, memorizing, and using “templates” rather than specific results.
- LLMs Do Not Think Step-by-step In Implicit Reasoning. They argue that while explicit chain-of-thought (CoT) generates stepwise reasoning, implicit reasoning (e.g. model trained to reproduce CoT outputs) does not internally invoke the same stepwise process.
- Inference Scaling FLaws: The Limits of LLM Resampling with Imperfect Verifiers. Notes that inference-time scaling is limited by the quality of the verifier (at least for approaches relying on verification).
LLM
- Nvidia releases: Hymba Hybrid-Head Architecture Boosts Small Language Model Performance (code). Combines transformer attention mechanism with state-space models (SSMs, c.f. Mamba) to achieve high performance.
- Ethan Mollick provides some practical advice for prompting LLMs: Getting started with AI: Good enough prompting (Don’t make this hard).
- A sub-culture of AI enthusiasts has developed around the idea of simply giving modern LLMs (limited though they may be) autonomy; or at least semi-persistence by allowing them to run for long time periods. Often, the AIs behave in strange and unexpected ways, as they attempt to continue a token-chain well beyond their original training/design.
- Infinite Backrooms generates extremely long conversations by creating chat-rooms where different LLMs talk to each other endlessly. Conversations often veer into strange and unexpected topics; with some LLMs even outputting tokens describing distress.
- truth_terminal is an 𝕏 handle that is reportedly an LLM given free reign to post. However, there is speculation that the human in charge (Andy Ayrey) is selective about what it actually posts.
- Venture capitalist Marc Andreessen gave the AI a $50,000 no-strings grant (in Bitcoin), so that it could pursue whatever actions it wanted.
- The bot started a memecoin (GOAT) that briefly reached a market cap of $1.3B (currently still at >$700M). The coin’s name is a reference to a (NSFW) shock-meme. The AI itself (or the human behind it) likely netted many million $.
- The AI reportedly “kept asking to play video games”; so it was given access to an “arcade” where the games are text-based games generated by another LLM. You can watch the streaming interactions: Terminal TV.
- It also has its own web-page (that it, ostensibly, authored).
- While it is hard to know how much human tampering is occurring in these implementations, it is interesting to see the bizarre and unexpected outputs that LLMs generate when unleashed.
- AI models work together faster when they speak their own language. Letting AI models communicate with each other in their internal mathematical language, rather than translating back and forth to English, could accelerate their task-solving abilities.
- Preprint: DroidSpeak: Enhancing Cross-LLM Communication.
- Although allowing AIs to converse in an invented language could increase efficiency, it undercuts the legibility and auditability aspects of natural-language inter-communication. Overall, this approach could thus hamper both safety and capabilities of complex AI ecosystems.
- Anthropic describes Model Context Protocol: an open standard for secure, two-way connections between data sources and AI (intro, quickstart, code).
- Anthropic adds a style feature, where it will try to mimic a provided writing example.
- Further evidence that model quantization can subtly impact performance: Aider reports that Details matter with open source models.
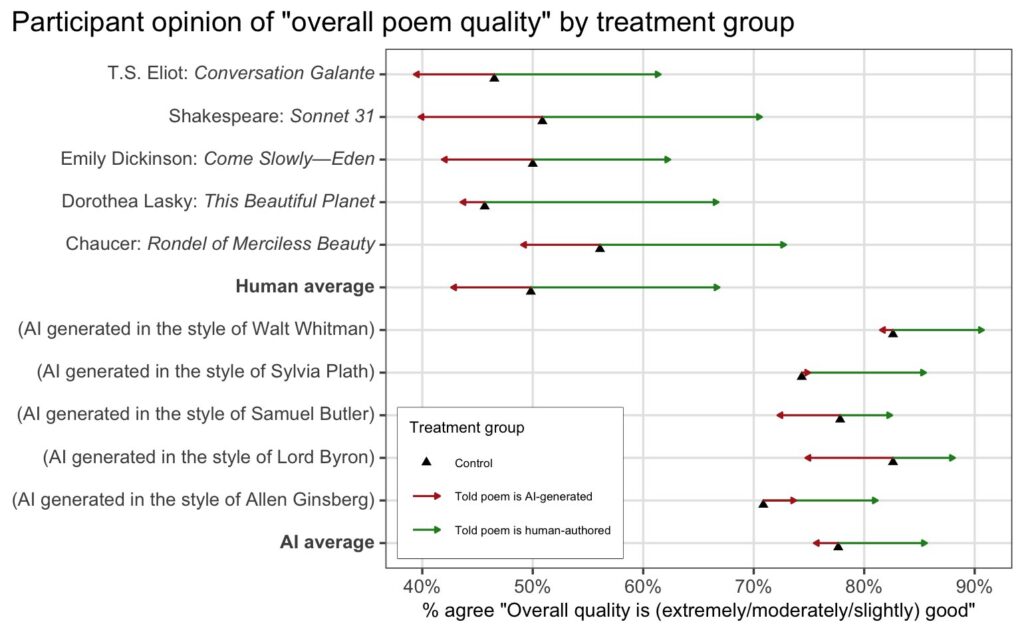
- As a follow-up to last week’s paper on poetry (AI-generated poetry is indistinguishable from human-written poetry and is rated more favorably); Colin Fraser provides this summary graphic, highlighting that humans objectively prefer AI poetry, but when told authorship (real or not), they rate things more highly when (ostensibly) made by humans and lower when (ostensibly) made by AI.
AI Agents
- DynaSaur: Large Language Agents Beyond Predefined Actions. The agent improves capabilities over time by progressively writing more functions/code.
Image Synthesis
- Black Forest Labs released FLUX.1 Tools, a suite of models to enable more control over image generation/editing (inpainting, outpainting, conditioning).
- Runway Frames is a new image model, with good style control.
- OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (code, demo). Allows one to modify a person/character’s clothes in an image.
- There are other codebases to do similar things; e.g.: Kolors Virtual Try-On in the Wild.
Audio
- ElevenLabs announces a podcast generator (competing with Google’s Notebook LM).
Video
- Meta’s Segment Anything Model 2 (SAM2) has been adapted, adding motion-aware memory, which allows it to do zero-shot video masking (another example): SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory (code).
- Runway adds Expand Video, allowing one to change aspect ratio by outpainting (e.g.). Includes prompt guidance, allowing one to change a shot significantly.
- LTXStudio announce LTX Video, an open-source video model (code, docs). Although the quality is not quite state-of-the-art, it is remarkably good and it is real-time. Of course, not all generations are excellent; but the real-time generation speed points towards neural world simulation in the not-too-distant future.
- Luma Dream Machine v1.6, including Luma Photon image generation and consistent characters.
- A group claims to have leaked access to a turbo version of OpenAI’s Sora video model (examples).
World Synthesis
- An interesting result: using Runway’s outpainting on video where a person’s face is barely visible (and distorted through refraction); the reconstructed face is remarkably coherent/correct. This implies that the model is implicitly building a valid world model.
- Google et al present: CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models (project page with examples). Follow up to early CAT3D; but now the 3D objects can evolve in time.
Science
- Large language models surpass human experts in predicting neuroscience results (writeup: AI can predict neuroscience study results better than human experts, study finds). This once again shows that LLMs can implicitly learn valid generalizations, picking up on subtle trends spread across a dataset.
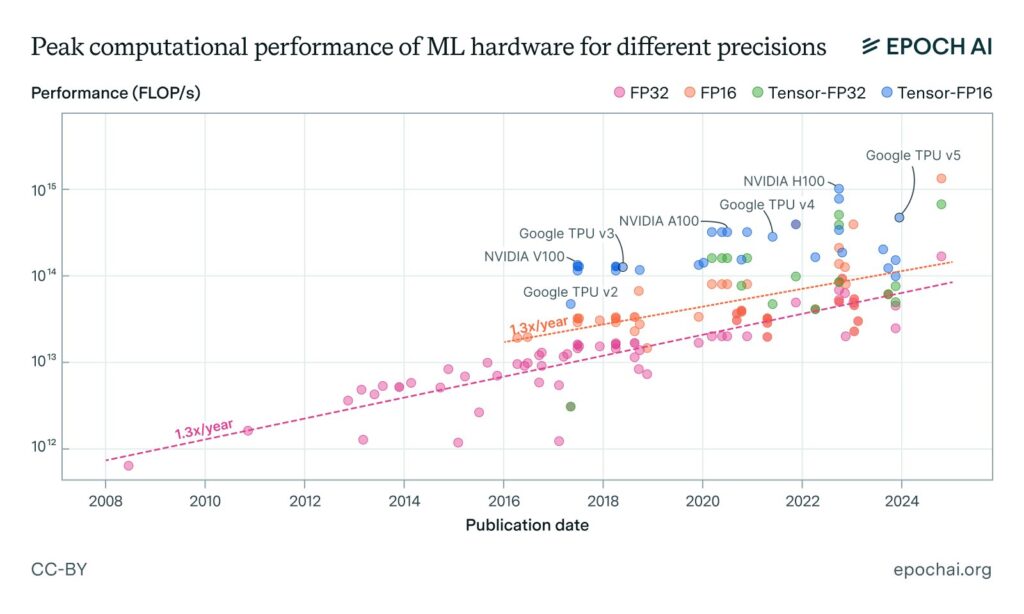
Hardware
Robots
- Although the Unitree G1 humanoid robot was announced with a price of $16k (c.f.), the latest price chart shows a range of configurations, with prices from $40k to $66k.
- Mercedes is running a trial for use of Apptronik robot in their Austin lab.