
General
- The End of Productivity: Why creativity is the new currency of success. The essay argues that focus on pure productivity (and metrics) misses the things that humans value most. And that, potentially, the era of AI will actually shift in an emphasis from human productivity to human creativity being the focus of value.
- An interesting experiment (assuming it’s true): an AI jailbreaking contest. An AI agent was tasked with not approving an outgoing money transfer. Anyone can spend a small amount of money to send the AI a message. The money is added to the pool, and the cost-per-message increases slightly. It started at $10/message, and quickly grew to $450/message with a prize-pool of $50k. At that point, someone tricked the AI by sending a message that explained an inverted meaning of approveTransfer. So, they won the money.
- This acts as the usual reminder that modern LLMs are not robust against dedicated attackers that seek to trick them and extract information.
- Reportedly: Elon Musk lands priority for Nvidia GB200 delivery in January with US$1.08 billion. Paying a premium to get earlier access to next-gen chips may well be a good strategy.
- An interesting blog post by Lilian Weng: Reward Hacking in Reinforcement Learning. Some notes about modern RLHF applied to LLMs (based on this paper):
- RLHF increases human approval, but not necessarily correctness.
- RLHF weakens humans’ ability to evaluate: The error rate of human evaluation is higher after RLHF training.
- RLHF makes incorrect outputs more convincing to humans. The evaluation false positive rate significantly increases after RLHF training.
- Andrej Karpathy provides an interesting historical look at how the transformer architecture was invented (c.f. Attention Is All you Need.)
- A critical analysis of “openness” in AI: Why ‘open’ AI systems are actually closed, and why this matters. They note that the current version of “open” does not preclude concentration of power.
Research Insights
- Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
- Reverse Thinking Makes LLMs Stronger Reasoners. Humans reason not just from problem-to-solution, but also from solution backwards.
- Last week saw many results attempting to replicate OpenAI o1’s reasoning ability. Now we also have: o1-Coder: an o1 Replication for Coding (code).
LLM
- Amazon enters the fight with Nova (docs, benchmarks). Although not leading on benchmarks, they promise good performance-per-dollar; will be available on Amazon Bedrock.
AI Agents
Audio
- Hume adds a voice creation mode where one can adjust intuitive sliders to pick out the desired voice.
- ElevenLabs previously announced intentions to build a conversational AI platform. This capability is now launching; they claim it their interface makes it extremely easy to build a conversational voice bot, and allows you to select the LLM that is called behind-the-scenes.
Video
- Google et al. show off: Generative Omnimatte: Learning to Decompose Video into Layers (preprint). It can separate a video into distinct layers, including associating affects (e.g. shadows) with the correct layer (parent object), and inpainting missing portions (e.g. occluded background). Obvious utility for visual effects work: can be used to make a particular person/object invisible (including their shadows), to apply edits to just one component (object or background), etc.
- Invideo are demoing a system where a single prompt generates an entire video sequence telling a story (example). I think that creators generally want more granular control of output so they can put together a precise narrative. But there are use-cases where this kind of fully automated generation may make sense.
- It’s easy to look at the output and find the visual or narrative flaws. But also interesting to remember how advanced this is compared to what was possible 6-9 months ago. There is obviously a huge amount of untapped potential in these kinds of systems, as they become more refined.
- Runway tease a prototype for a system to enable control over generative video, where videos are defined by keyframes and adjusting the connection/interpolation between them (blog post).
- In October 2023, there were some prototypes of a “prompt travel” idea wherein a video was generated by picking a path through the image-generation latent space. One would define keyframe images, and the system would continually vary the effective prompt to interpolate between them (preprint, animatediff-cli-prompt-travel). This provided a level of control (while not being robust enough to actually enforce coherent temporal physics). Runway’s approach (leveraging a video model) may finally enable the required control and consistency.
- Tencent announce an open-source video model: Hunyuan Video (example, video-to-video example).
World Synthesis
- World Labs (which includes Fei-Fei Li) is working on 3D world generation from a single image (examples, more examples).
- Not to be outdone, Google then announced: Genie 2: A large-scale foundation world model, which can generate playable worlds.
Science
- Google Introduces A.I. Agent That Aces 15-Day Weather Forecasts. Scientific paper: Probabilistic weather forecasting with machine learning.
Brain
- Whole-brain mapping is advancing. We recently saw release of a fly brain map (140,000 neurons). Now, a roadmap effort claims that whole-brain mapping for mammalian brains should be possible in the coming years.
Hardware
- ASML released a hype-video describing the complexity of modern lithography (in particular the computational lithography aspect). There is no new information, but it’s a nice reminder of the nature of the state-of-the-art.
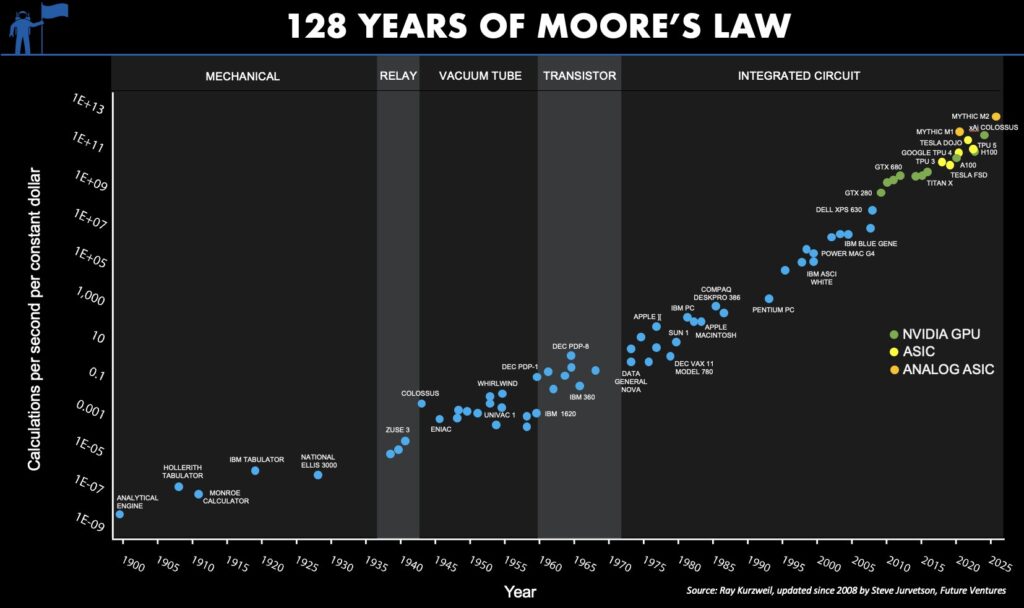
- I never grow tired of looking at plots of Moore’s Law:
Robots