
General
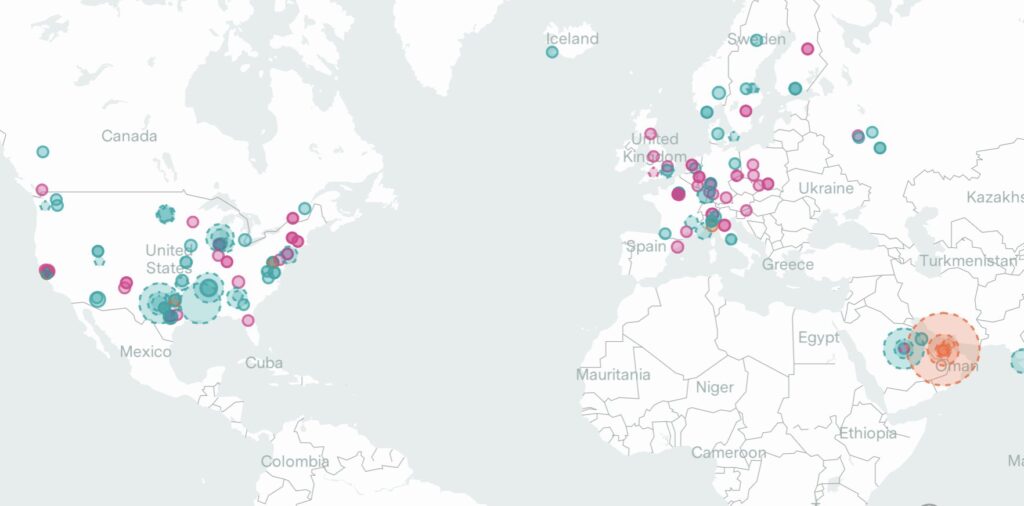
- Analysis of the location of datacenters (750 AI supercomputers): Trends in AI Supercomputers.
Research Insights
- Prompting Science Report 2: The Decreasing Value of Chain of Thought in Prompting. Reasoning models don’t benefit from “think step by step” prompting.
- Epoch AI was given access to the full reasoning traces of o3-mini (normally only summaries are shown to the user) to conduct this research: Beyond benchmark scores: Analyzing o3-mini’s mathematical reasoning. Mathematicians reviewed the traces of working on math problems; one evaluated described o3 as a “vibes-based inductive reasoner”.
- Corrector Sampling in Language Models. Resampling prior tokens can be used to do small amounts of backtracking and thereby improve performance.
- SPARTA ALIGNMENT: Collectively Aligning Multiple Language Models through Combat. The models compete and evaluate each other, without requiring external (human) scoring; models are updated on the computed preference ordering. This seems to provide a simple way to recursively self-improve.
LLM
- Anthropic adds Claude Gov; models intended for national security.
- Mistral announces Magistral, a reasoning model. Two variants: 24B open-source or a larger enterprise version via API.
- An interesting result from the report (section 7.2: Eating the multimodal free lunch): They base model is multi-modal, but RL is done using text only. Yet, they observe this text-only training does not harm multi-modal performance; in fact multi-modal performance improves. This suggests modalities are well-entangled and that transfer learning between modalities is naturally occurring.
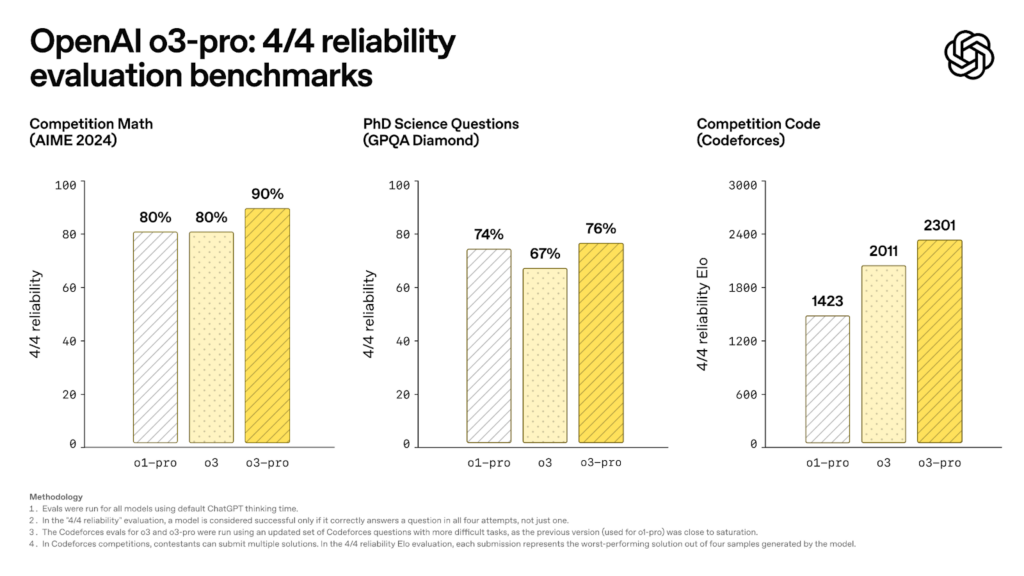
- OpenAI announced the released of o3-pro (release notes).
- Review from an early tester: God is hungry for Context: First thoughts on o3 pro.
Vision
- Meta announce V-JEPA 2 (paper) a vision model that builds a world model, and could be useful for robotic control.
Audio
- ElevenLabs introduces v3, an expressive text-to-speech system that supports intonation, accent, and even non-words like laughs and sighs or sound effects (examples: joke, affecting accents, various).
World Synthesis
- 4DV is demoing 4D Gaussian Splatting, wherein multi-camera video data is converted into a temporal/video 3D-spatial reconstruction (videos showing interaction: 1, 2, 3).
Science
Cars
- Tesla has provided some updated details on their current “full self-driving” (FSD) implementation. Some claims: 3.5B miles driven by FSD across 6 million vehicles, 54% safer than human.
Robots
- Video of Figure 02 robot sorting deformable packages. (Uncut 1 hour video of this activity, proving the prior footage was not cherry-picked.)
- 1X announce Redwood, their vision-language transformer model for robot control.