
General
- The mysterious startup SSI (Safe Superintelligenc Inc.), founded by Ilya Sutskever after leaving OpenAI, has released a small update. The news is that SSI has raised $1 billion to pursue safe AI systems (at a reported $5 billion valuation). SSI’s stated goal is to directly develop safe ASI (with “no distraction by management overhead or product cycles”).
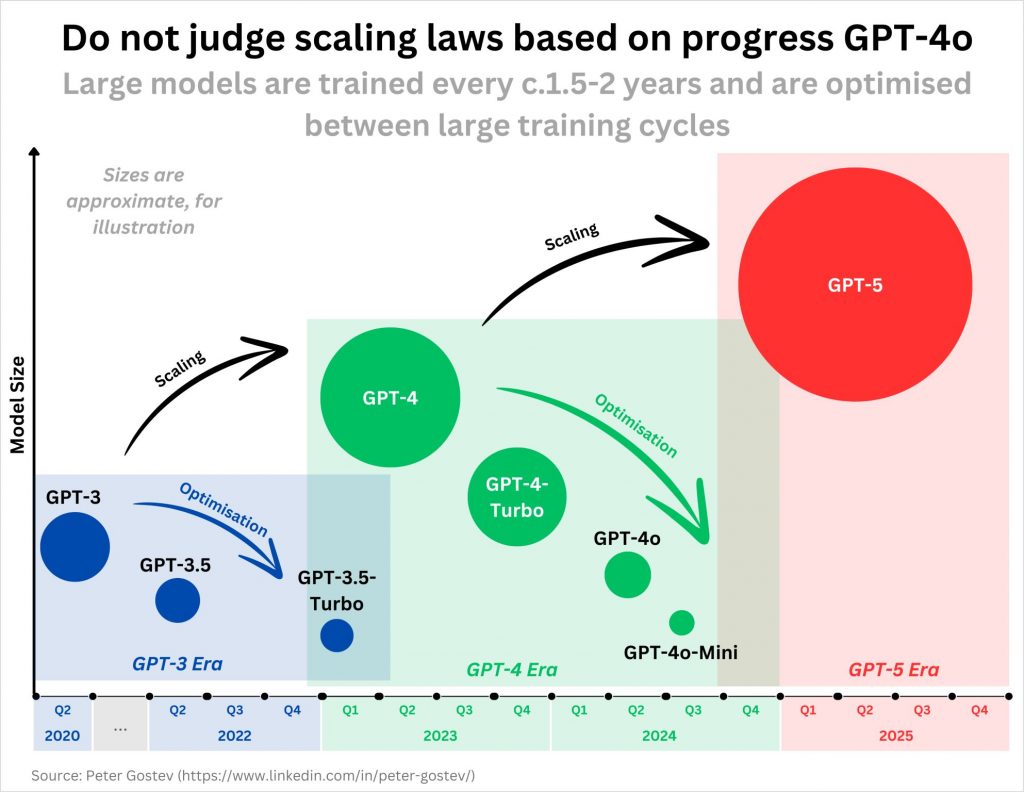
- Peter Gostev has a nice reminder (LinkedIn post) that assessing scaling should be done based on subsequent generations of larger models, and not mislead by the incremental refinement of models within a generation.
LLM
- Magic.dev (who develop code-focused LLMs) report LTM-2-Mini, an LLM with 100M token context window (roughly 10 million lines of code).
- Amazon is working with Anthropic to use Claude as the interface in the future for Alexa.
- Anthropic artifacts can now be edited in-situ: highly a section and ask Claude to explain or modify.
- Including AI tools in a spreadsheet interface is being offered by V7 Go and Otto. Now, Paradigm is similarly offering AI-enhanced workflows in a spreadsheet UI.
- Release of: OLMoE: Open Mixture-of-Experts Language Models (code). Open-source 7B model (using only 1B per input token).
- Anthropic announced Claude for Enterprise: higher security, github integration, and 500k context windows.
- OthersideAI (creators of HyperWrite) and Glaive released an open-source model: Reflection-Llama-3.1-70B. “Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.” It is a fine-tune of Llama 3.1 that trains-in a form of chain-of-thought/self-reflection where the model outputs inner monologue thoughts before giving a final answer (2023 paper describing method). They claim it out-performs other open-source models (top results on MMLU, MATH, IFEval, GSM8K), and even beats closed models (GPT-4o) in some ways, despite being only 70B parameters (demo here, or here). They will release a Reflection 405B model soon trained using the same method (which will presumably be even better). If an open-source model dramatically out-performed all available models, that would be big news indeed.
Multi-modal Models
- Mini-Omni is an open-source real-time conversational model: Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming (model, code).
AI Agents
- Altera claims that their Project Sid is the first simulation of 1,000+ AI agents operating autonomously and interacting with one another. They further claim observing the emergency of a simple economy, government, and culture.
- Honeycomb demonstrated an AI agent (that integrates GitHub, Slack, Jira, Linear, etc.) with record-setting performance on SWE-bench (19.8% to 22.1%); technical report here.
- Replit announces Replit Agent early access. The claim is that they automate the process of setting up dev environments (and configure database, deploy to cloud, etc.), so the AI Agent can then fill it in with the user-requested code, and thus build an app from scratch.
Science
- Google DeepMind announced AlphaProteo, which can predict novel proteins for target bio/medical applications (paper).
Policy
- Early 2024 reports of ChatGPT’s death were greatly exaggerated. ChatGPT usage has doubled since last year.
- The Beijing Institute of AI Safety and Governance was announced.
Human Factors
- It is well-known that eyewitness testimony from humans is unreliable, in large part because humans can be induced to generate false memories. A new study: Conversational AI Powered by Large Language Models Amplifies False Memories in Witness Interviews. The ability of LLMs to be persuasive and enhance the false memory effect is not so surprising. It does, however, amplify the safety concern regarding AIs eventually having superhuman persuasion.
- Study released: The Effects of Generative AI on High Skilled Work: Evidence from Three Field Experiments with Software Developers. They report a 26% increase in task completion for coders using GPT-3.5. Given how much better modern LLMs are (e.g. Cursor+Sonnet-3.5), this +26% is a strongly positive indicator of AI economic value.
Image Synthesis
- fal.ai offers quick-and-easy fine-tuning (LoRA) of FLUX image models (roughly $2 and 5 minutes to get a tuned model).
Audio
- Neets.ai offers text-to-speech (TTS) via cloud API at a remarkably low cost of $1/million characters (by comparison, ElevenLabs charges ~$50/million characters).
Video
- RunwayML now allows video generations to be extended to 40 seconds.
- New text-to-video system: Minimax (requires Chinese phone number to use). Example outputs. Appears roughly competitive with the state-of-the-art of publicly-usable models.
- Luma upgraded their Dream Machine to v1.6, including the addition of specific camera controls (pan, zoom, etc.) for greater control.
- Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency (preprint). Improved animation of a portrait, that adheres to the provided audio clip.
- More examples (c.f. evolution of capabilities) of modern genAI video quality, when some effort is put into the work:
- Space colonization
- Consistent characters
- Sea monsters
- Music video
- Animated characters
- AI influencer
- Ten short examples
- Seven examples
- Clip from horror film
- “Gone” featuring astronaut and something ethereal
- Two dancers (surprisingly good consistency despite movement)
- Music video about flying
- The Paperclip Maximizer
- La Baie Aréa
- “To Dear Me” by Gisele Tong (winner of AI shorts film festival)
World Synthesis
- ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model (preprint).
- Further progress on reconstructing a 4D (environment over time) world. OmniRe: Omni Urban Scene Reconstruction (preprint, code).
- Last week saw a diffusion model that could simulate the Doom video game. Now, a diffusion model that can simulate frames from Super Mario Bros. (preprint). Although such things are currently just neat curiosities, they point towards the ability of these models to learn meaningful predictive “physics” appropriate to the particular dataset.
- DigitalCarbon is a startup commercializing the conversion of 2D images into 3D editable models (video).
- This video shows a demo implementation of ray-tracing (reflections, refractions) for a Gaussian splat environment.
Hardware
- xAI announced bringing online their training cluster (“Colossus”), which has 100,000 H100 GPUs (total ~100 exaflops FP16 compute). This makes it the largest (publicly-disclosed) AI training cluster.
- There are fresh rumors about OpenAI developing custom chips. This time, the claim is that they intend to build on TSMC’s upcoming A16 technology.
- The Daylight Computer ($730) is an attempt to build a tablet that is focused on long-form reading and eschewing distraction. People seem to like it (Dwarkesh Patel, Patrick McKenzie). There are plans to add some light-touch AI features (in-context summarization/explanation/etc.).
Cars
- Tesla announced Actually Smart Summon, which allows the vehicle to navigate from a parking spot to the user.
Robots
- This video talks about GXO has been testing multiple robots in their Spanx warehouse: Digit, Reflex, and Apollo.
- PNDbotics released a video showing progress on their humanoid design.
- 1X just unveiled their updated Neo humanoid design. The clothes-like cladding and smooth motion are intended to evoke a safe and friendly vibe. Additional short videos: doing some chores, making coffee (note hand dexterity), walking slowly. Longer video describing their approach to humanoid robot design.