
Research Insights
- Whiteboard-of-Thought: Thinking Step-by-Step Across Modalities. Gives LLM the ability to think through an answer visually by writing code that outputs images, and then analyzing said image. Combined with iterative self-prompting, this should allow a model to reason visually. It of course makes sense that an LLM would have trouble with visual tasks, which humans typically solve by visually imagining the problem. Of course, one can also train multimodal (text+vision) models; but even in that case there is likely an advantage to models using internal scratch-space to work through problems before answering.
- Predicting vs. Acting: A Trade-off Between World Modeling & Agent Modeling. RLHF is used to elicit desired behavior from base models. However, this leads to a tradeoff, where the agentic RLHFed model is better at the selected tasks, but becomes worse at generic next-token prediction and thus worse at world modeling. So goal-directed behavior worsens overall understanding. An obvious solution is to build systems that mix models. E.g. an agentic RLHFed system that can call a powerful base model for predictions.
- My own suggestion is to build swarms of AI agents, each specialized in some way. It does seem like we should keep the untuned base model available as an agent or tool in the mix; supervised by other agents.
- A set of nominally unrelated results all point in a similar direction:
- Mixture of A Million Experts. Google DeepMind shows that one can replace the feedforward layers in a transformer with a PEER layer (parameter efficient expert retrieval). The PEER layer draws from a large pool (over a million) of “tiny experts”. This outperforms feedforward, and also the usual coarse-grained mixture-of-experts (MoE) method.
- Memory3: Language Modeling with Explicit Memory. LLMs have different kinds of memory: contextual (current state captured by activation of key-value in transformer), implicit (baked into the network weights), and retrieval (if RAG systems pull in documents into context window). This work proposes to add another form of memory that is more robust/concrete than implicit (weights). During training, they learn a sparse attention key-values (highly compressed and efficient); during training, memories are retrieved and integrated into self-attention layers.
- Learning to (Learn at Test Time): RNNs with Expressive Hidden States (summary from one of the authors). This method introduces Test-Time-Training (TTT) layers into a recurrent neural network (RNN). So the hidden state (memory) of the RNN, instead of being a simple vector, is a small neural network. This internal NN is optimized via gradient descent to capture the required “current state” information as a long sequence of tokens is processed. This provides better expressive/memory power, while retaining the good scaling of RNNs for long sequences. The authors claim this yields much better scaling on long context-window problems than transformers or even Mamba (a structured state space model). TTT replaces the need for attention. Of course, transformers have many advantages; so it remains to be seen if TTT can match the capabilities of transformer systems. But it seems clever (and the general idea of having some NNs that learn to capture active state, inside of larger pretrained systems, could be useful).
- The common thread is increasing sophistication for the internal modules of a NN, with the internal weights being updated at runtime. This massively expands the expressive power of the system, without correspondingly increasing model size (since the larger range of possibilities is externalized). This seems like an attractive concept for improving LLMs.
- Distilling System 2 into System 1, uses LLM to do (expensive) “system 2 reasoning” by askingfor chain-of-thought solutions. Then retrains the system on that text. Thus, improved system 2 reasoning becomes baked-in to the LLM’s fast/reflexive response. Clever, useful, and points towards recursive self-improvement of LLMs. (Similar to STaR.)
- Associative Recurrent Memory Transformer. Tackles long-context windows by combining transformer self-attention for local context, with segment-level recurrence to capture distributed information. They show results for a 50M token context.
Safety
- It’s not easy to imagine how humans will provide suitable oversight to LLMs as they become smarter and more broadly deployed. One strategy is to have LLMs debate with each other, allowing the human to judge which argument is best even in instances where they don’t fully understand the topic. (C.f. Debate Helps Supervise Unreliable Experts, Debating with More Persuasive LLMs Leads to More Truthful Answers.) New Google DeepMind contribution: On scalable oversight with weak LLMs judging strong LLMs.
- Yoshua Bengio provides balanced arguments for why we should take AI safety seriously.
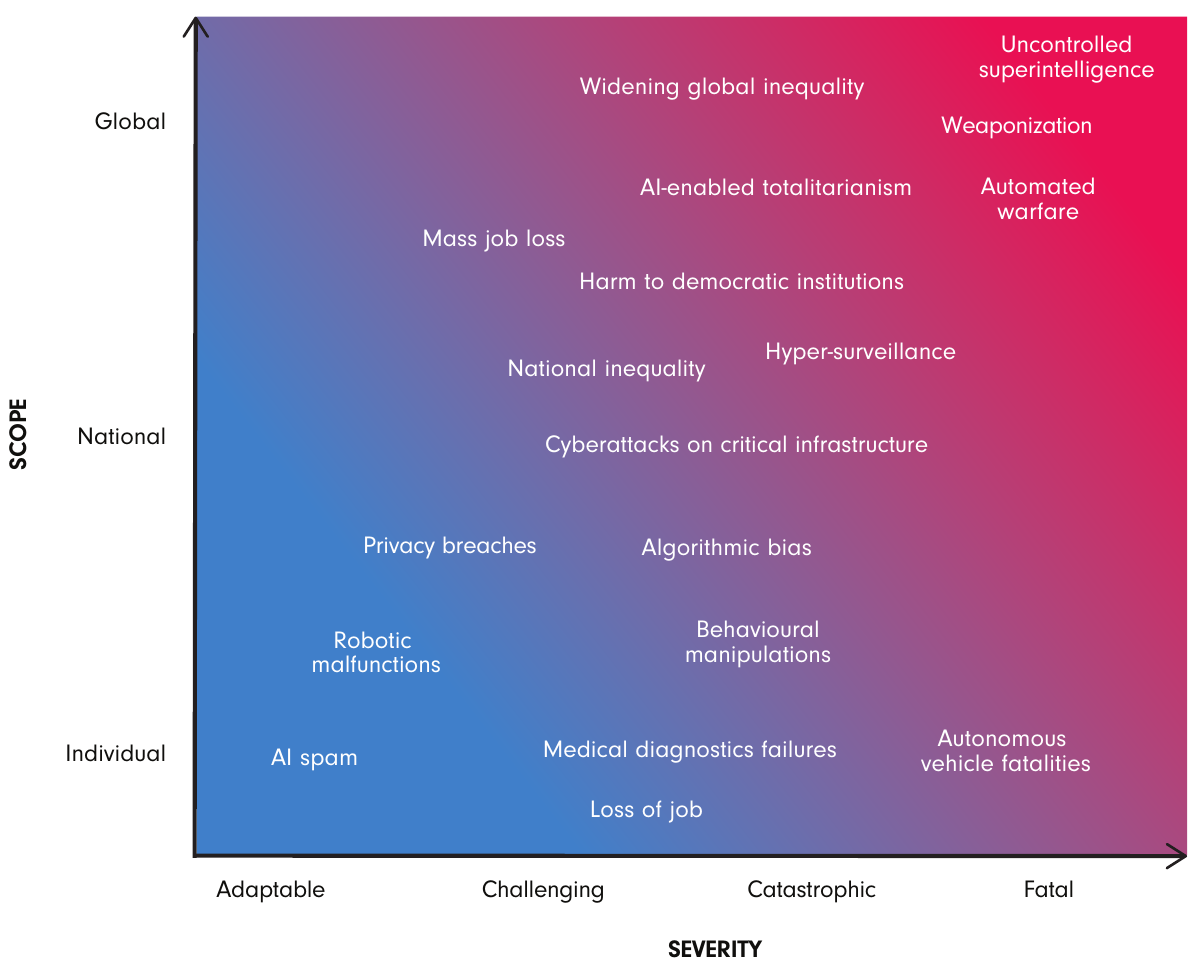
- CIGI paper: Framework Convention on Global AI Challenges. Discusses both near-term challenges and long-term risks. This image summarizes risks:
Chatbots
- GPT-4o and Kyutai Moshi (c.f.) show a shift towards conversational/audio chatbots.
- This 2016 paper (via 𝕏) is relevant: Turn-taking in Human Communication – Origins and Implications for Language Processing.
- Most human conversation involves rapid back-and-forth; in fact the average speaking time for a person is only 2 seconds.
- This pace of switching is faster than possible for language encoding, and certainly for deliberative thinking. So, participants are instead predicting the other person’s speech and when their turn will come.
- Current chatbots are ill-suited to this modality. They monologue too much, their latency is still too high, they don’t handle interruptions well, and they are not actively predicting the user’s speech as they are talking.
- But, these are all solvable problems. It would certainly be interesting to see a class of models trained and tuned to exhibit true conversational dialogue.
- Swift is a very fast voice-bot demo (based on Groq, Cartesia, VAD, and Vercel). Code here.
Images
- Paints-UNDO is a new model can turn an image into a video sequence of steps needed to sketch it, refine it, color it, etc. (more examples, huggingface demo). This model is part of an exploration for AI to better understand how humans create artistic images. It could also be used, perhaps, to generate drawing tutorials for humans.
Video
- Now that numerous AI tools are available for video and audio (c.f.), creators are starting explore. Here are some example creations. Right now these are quite short-form, but as tools improve in controllability and speed, we can expect to see longer-form content.
- Live Portrait allows you to drive the facial animation of an image using a provided video (examples). Also available on replicate.
- RenderNet has a video face swapping tool.
- YouTube Erase Song tool allows one to remove music from video (while leaving other audio intact). The main use-case is to avoid copyright claims (e.g. from background music).
- Odyssey announced that they intend to release AI tools for “Hollywood-grade visuals”. They are training models that don’t just output text-to-video, but output intermediate representations (depth maps? meshes?), allowing the user to iteratively ask for AI refinements. The idea is to give the level of control and quality that prestige TV/movies demand. Currently it’s just a teaser video; no results to inspect or demos to play with. But it will be exciting if they can deliver on this idea.
3D
- Zoo has added text-to-CAD.
World Synthesis
- Segment Any 4D Gaussians (preprint) shows how to extract content from a 4D (3D reconstruction+time) clip, and copy-paste that content into another 3D/4D reconstruction.
- HouseCrafter: Lifting Floorplans to 3D Scenes with 2D Diffusion Models (preprint).
- GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting (preprint, code) applies the Gaussian splatting to two-dimensional data, using it as a compression algorithm. Seems to work quite well.
Art
- Style transfer is a well-studied class of methods for recreating an image with a different art style. It has somewhat fallen by the wayside since generative AI art (image synthesis) is now so good. But StyleShot shows improvements in style transfer (code, demo).
- Generative Art in Websim shows how to make generative art by prompting an LLM (such as Anthropic’s Claude chatbot).
AI for Science
- OpenAI and Los Alamos National Laboratory announce bioscience research partnership. (Same announcement from Los Alamos.) The focus is on bioscience research, and AI biosecurity. They also mention deploying the OpenAI multi-modal models (GPT-4o voice assistant) in real-world wet-lab settings, as a companion to the human scientist.
Health
- Sam Altman and Arianna Huffington announced a new AI-health venture: Thrive AI Health. The idea is hyper-personalization of AI to help people make behavioral changes for better health.
Brain
- Paper: Semantic encoding during language comprehension at single-cell resolution. Researchers measured single cells in the prefrontal cortex of live humans. The activation patterns suggest that specific neurons respond to word semantics. There is a strong analogy to what’s seem in LLMs. Concepts are encoded in activation patterns, with specific neurons capturing meaning (at some level of abstraction).
- Paper: Task-driven neural network models predict neural dynamics of proprioception. Writeup: Artificial intelligence meets body sense: task-driven neural networks reveal computational principles of the proprioceptive pathway. They use musculoskeletal modeling and neural networks to mimic proprioception.
- There is an interesting convergence (c.f.) between artificial neural networks and understanding of biological brains. The two efforts are complementary, helping us better understand AIs, better understand brains, and improve interfaces between them.
- Synchron is developing a brain-computer interface (BCI) that is inserted into blood vessels (like a catheter) and therefore doesn’t require open brain surgery. They are planning to use OpenAI technology to improve interface/control, since a chatbot can provide contextually meaningful options.
Robots
Robot control is advancing, with several methods showing promise.
- Diffusion methods show promise for planning, including for robots to generate path-plans in environments:
- C.f. Diffusion Forcing, which denoises tokens allowing arbitrary-length videos/plans to be generated.
- Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World.
- DiPPeST: Diffusion-based Path Planner for Synthesizing Trajectories Applied on Quadruped Robots.
- LDP: A Local Diffusion Planner for Efficient Robot Navigation and Collision Avoidance.
- As previously discussed, world reconstruction (via 3D Gaussian splats) is also relevant for robotic planning:
- Dynamic 3D Gaussian Tracking for Graph-Based Neural Dynamics Modeling. Can track object motion, including deformable objects, enabling improved planning.
- Reinforcement learning exploiting generative models is improving:
- New paper: Lifelike agility and play in quadrupedal robots using reinforcement learning and generative pre-trained models (Nature paper, preprint). They use a hiearchy of controllers, based on generative modeling (trained in part on animal motion).
Robot hardware/systems continue to advance.
- Most current robots lack a sense of touch. There are efforts to add pressure sensors. An alternative is for the robot to measure audio signals, and train models that can infer from that the necessary tactile information. ManiWAV: Learning Robot Manipulation from In-the-Wild Audio-Visual Data (preprint). Clever.
- Xiaomi claims they are bringing online a robot factory that will operate 24/7 without humans, delivering 60 smartphones/minute. I’m skeptical (I assume there will still be humans tasked with oversight, maintenance, repair, and intervention); but it is an interesting trend to watch.
- A new entrant to the humanoid-robot startup space: BXI Elf robot. Already available for purchase ($25k), though it seems a bit primitive compared to other efforts.