
Research Insights
- Paper from 2023: Self-Compressing Neural Networks. Puts the model size (in bytes) as parameter in training, so that it optimizes for a small NN (using quantization). Clever way to make models very small (example implementation, using tinygrad).
- Grokfast: Accelerated Grokking by Amplifying Slow Gradients. Novel approach is, instead of trying to improve model size/capacity, they modify the optimizer be biased against memorization and toward understanding.
- Grokking is the observation that during training, a model might first over-fit (effectively memorizing behavior), but thereafter (after much, much more training) slip into a more generalized and robust modeling/behavior. This thus represents a shift towards true understanding.
- Obviously an overall goal is to emphasize grokking in models and avoid rote memorization.
- This work analyzes the gradients during model optimization, decomposing them into fast gradients (which represent over-fitting) and a set of slower updates (that have to do with grokking). One can thus emphasize grokking (making it occur 50× sooner).
- However, there are concerns that the observed behavior could be an artifact of the setup.
- The context length is a critical parameter for an LLM, and larger context lengths are being demonstrated (unlocking new capabilities). However, larger context lengths often lead to progressively worse performance, where models fail to identify the right information in needle-in-haystack problems. Attention Overflow: Language Model Input Blur during Long-Context Missing Items Recommendation. Analyzes in detail, and shows how very long contexts can overwhelm attentional mechanisms, leading to (e.g.) forgetting that something had already been said/enumerated.
- Why Does New Knowledge Create Messy Ripple Effects in LLMs? Considers how adding new knowledge (editing a fact) can properly or improperly propagate to related bits of knowledge (ripples).
- System-1.x: Learning to Balance Fast and Slow Planning with Language Models. A common hope for future AI is to combine the strong reflexive/intuitive response of LLMs (equivalent to system 1 in humans) with some form of iteration/deliberation/search (system 2). System 1.x Planner is a framework that allows flexibility between approaches. Tasks are broken into plans, with each step being evaluated as easy (use system 1 methods) or complex (using system 2). The blending between the two is user-controllable. Show improvement on toy problems.
- Anthropic posted an update from their interpretability team: Circuits Updates.
- Diffusion Models as Data Mining Tools. Training a diffusion model for images is typically done for image synthesis (generate novel images). But the training of course learns many meaningful aspects of the data. So, in principle, one could use this training as a way to understand datasets. They show how the model can pull out representative image elements for a particular sub-domain, or to localize abnormalities in images (useful for medical images, for instance).
- Google publishes: Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. This adds to recent work (c.f.) about tradeoffs in training vs. inference compute. Google shows that there are scaling laws for inference-time compute.
- Similarly this was just released: An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models. They show that a smaller model combined with search is Pareto-optimal (similar to this result).
- Google DeepMind publishes: Diffusion Augmented Agents: A Framework for Efficient Exploration and Transfer Learning (project page). They combine language-vision models with diffusion models to generate visual data. This allows agents to learn in simulated physical environments.
LLMs
- PyTorch released torchchat, which makes it easy to install and run LLMs locally.
- sqlite-vec is an extension to the popular SQLite, that enables vector database retrieval that is local and very fast.
- With the cost of LLM inference dropping rapidly (Llama 3 8B, 4o-mini, Gemma 2 2B, etc.; hardware acceleration via Cerebras, Graphcore, Groq, etc.), it is increasingly attractive to brute-force problems through iteratively calling the LLM (many-shot, etc.). Greenblatt claimed good performance on ARC-AGI by brute-force writing/testing programs. Hassid et al. showed tradeoffs between model size and iteration (with repeatedly calling smaller models often better). Brown et al. showed scaling of sampling inference (c.f.). This post claims a simple method: give the LLM a problem, and just repeatedly ask it to improve code (“fix bugs, add features, …”). (Final app, iteration code, even better result using Claude 3.5 Sonnet.) Even without any feedback (from human or code execution), the code becomes better over time. This approach is overall “inefficient” in the sense that more optimal workflows no doubt exist. But with LLM inference quite cheap, generate decent solution in this manner seems viable.
- Aidan McLau tries to address the disconnect between existing benchmarks (or the preference-ratings of lmsys arena) and the vaguer sense that some models are notably better at creative or reasoning tasks. Aiden-Bench asks a given LLM some questions repeatedly, evaluating whether they can continue generating novel (but coherent) answers. Notably, these scores are quite different than conventional (lmsys) scores. Mistral Large 2 wins, GPT-4 performs better than GPT-4o, but 4o-mini does well considering its size.
- LangChain announced LangGraph Studio, an IDE for designing agent workflows.
- OpenAI introduces structured outputs to their API, so that one can force outputs to follow a strict JSON schema.
- A recent paper notes that enforcing format restrictions on an LLM reduces quality: Let Me Speak Freely? A Study on the Impact of Format Restrictions on Performance of Large Language Models. This is perhaps not surprising, since you are constraining token output to a lower-probability branch (otherwise you wouldn’t need the constraint), which will thus not be the optimal/trained output. Nevertheless, this might still be the strongest possible answer within the constraints of the schema. Conversely, one can use a chain-of-thought solution where the model generates its best free-form answer, and then reformulates it into the rigid schema.
- Open-source code to implement structured LLM outputs.
- The new schema-compatible model gpt-4o-2024-08-06 also has slightly higher performance and is half the cost for inference.
- There are a few results showing that LLMs can predict the outcome of social science experiments: model human, virtual worlds, social predictors, predict surveys/experiments (demo). This is expected in the sense that the LLM is model fit to aggregate human outputs; but also neat in the sense that one can ask new questions and get decent predictions. Of course one should still conduct new experiments to fill in novel parts of the space.
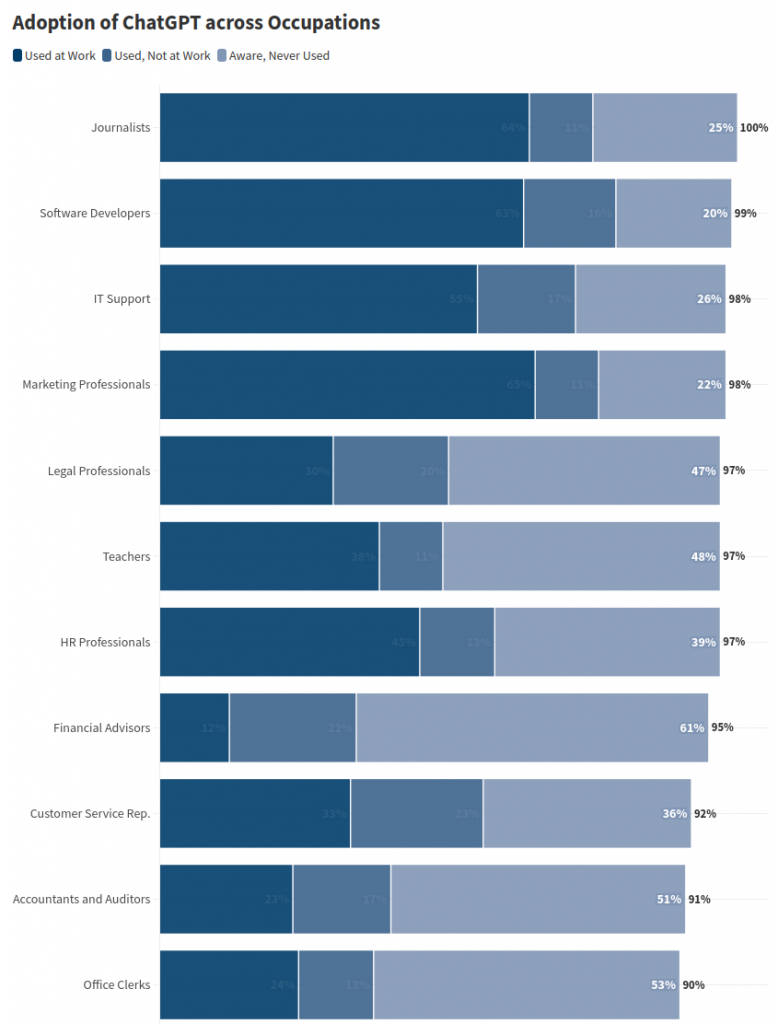
- Research brief: The Adoption of ChatGPT. Usage is quite high (especially among jobs that are most impacted by AI replacement). There is a surprisingly large gender gap (male usage 20% higher than female).
Voice
- Dialog is central to human communication (average human speaking time in conversation is only 2 seconds, c.f.). Older chatbots would explicitly transcribe voice and feed it to an LLM, and convert the respond to audio using TTS. This is slow and loses the nuance of language. More modern chatbots directly tokenize the audio stream (moshi, rtvi-ai, 4o). A new paper takes this even further: Language Model Can Listen While Speaking. This goes beyond turn-based dialog, allowing the model to speak and listen simultaneously, so that conversation can overlap naturally.
Safety
- Dan Hendrycks et al. publish preprint: Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress? They find that ~50% of benchmarks do not meaningfully measure safety progress.
- Tamper-Resistant Safeguards for Open-Weight LLMs (project, code). They train a network in a way that certain behaviors/outputs are suppressed, and cannot be recovered via fine-tuning. They do this through adversarial training against tampering attacks, where a tampering-resistant loss is added. If this pans out, it is good news for continued release of open-weight models.
- OpenAI plans partnering with the US AI Safety Institute. This would give the US government early previews of models, so that they can contribute to safety testing.
Image Synthesis
- Black Forest Labs (which includes many of the original Stable Diffusion folks) unveiled Flux, a state-of-the-art open-source image model. Outputs seem quite good. They are planning to work on text-to-video. Flux.1 is available on fal.ai and replicate.

Vision
- Last week, Segment Anything Model v2 was released; and the idea was floated to use this for medical imaging. Now some folks have released a preprint: Medical SAM 2: Segment medical images as video via Segment Anything Model 2 (code). SAM2 can be used for one-click segmentation of 3D elements in medical scans. Can also be used for one-shot identification of target features in images. Impressive.
Video
- As AI video systems improve, a possible near-term use-case is to add visual effects to otherwise conventional live-action video (example).
3D
- MeshAnything V2 improves upon the automatic conversion of point-clouds into traditional meshes (preprint, demo).
Science
- Google published: Neural general circulation models for weather and climate. This neural climate model gives high prediction accuracy for short-term weather, and also for medium or long term climate.
- Diffusion models for image synthesis work by training a system to remove noise from corrupted images. This paper applies this logic to chemical structures; training a diffusion model to simulate molecular relaxation as a ‘denoising’ of distorted molecular structures. Efficient way to compute molecular structures.
Hardware
- Publication in npj unconventional computing: Experimental demonstration of magnetic tunnel junction-based computational random-access memory. Computing elements that combine memory and logic in a single unit would save a lot of energy/time wasted in conventional von Neumann architectures that shuttle data from system memory to compute elements. This paper provides an experimental demonstration of computational memory elements (CRAM). Interesting possible direction for future neural accelerators.
- Nvidia’s Blackwell GPUs will be delayed by at least 3 months as they address a design flaw. Enormous orders have been put in (by Google, Microsoft, etc.), so all those AI efforts will correspondingly be delayed.
Robots
- Neura released a video of their 4NE-1 humanoid robot.
- UBTECH reports that their Walker S Lite worked in a real factory for 21 days as a demo.
- Figure released a video for their new Figure 02 humanoid robot. More capable than previous version. Has onboard compute for inference (including doing tasks and voice-to-voice interaction with human operator). It is not yet available for purchase, but is being used in a test mode in a BMW plant. Another step towards commercial humanoid robots.