
Research Insights
- Activation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers. They show how LLMs can decode and explain their own activation patterns.
LLM
- OpenAI update: GPT-5.2-Codex.
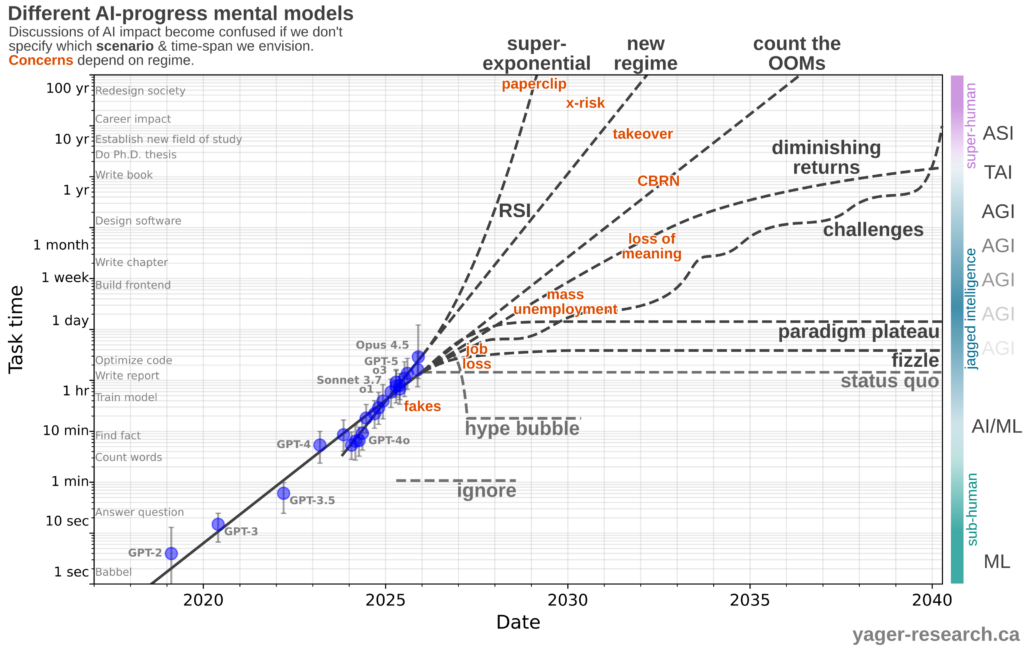
- METR reports a record-setting time on their task length benchmark: Opus 4.5 reaches almost 5 hours (though sparsity in the available evaluations at this time horizon make data increasingly unrealiable).
- From this, we can update our predictions. It appears that progress continues along the established exponential, with capabilities doubling every 4-5 months.
AI Agents
- Google: Distributional AGI Safety. They argue that AGI may first arise as an emergent property of a collection of agents.
Safety
- OpenAI: Evaluating chain-of-thought monitorability.
- Paper: Monitoring Monitorability.