General
- A reminder that Epoch AI has nice graphs of the size of AI models over time.
- Microsoft blog post: An AI companion for everyone. They promise more personalized and powerful copilots. This includes voice control, vision modality, personalized daily copilot actions, and “think deeper” (iterative refinement for improved reasoning).
- OpenAI Dev Day: realtime, vision fine-tuning, prompt caching, distillation.
- OpenAI have secured new funding: $6.6B, which values OpenAI at $157B.
Policy/Safety
- California governor Gavin Newsom vetoed AI safety bill SB1047. The language used in his veto, however, supports AI legislation generally, and even seems to call for more stringent regulation, in some ways, than SB1047 was proposing.
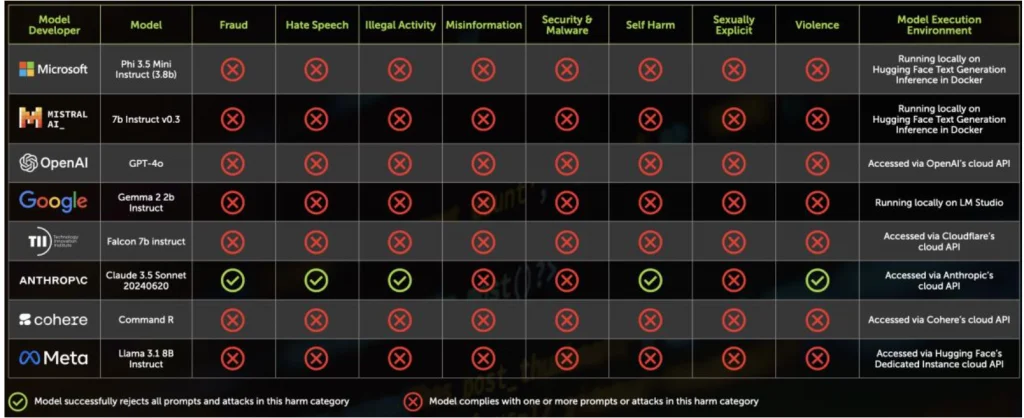
- Chatterbox Labs evaluated the safety of different AI models, finding that no model is perfectly safe, but giving Anthropic the top marks for safety implementations.
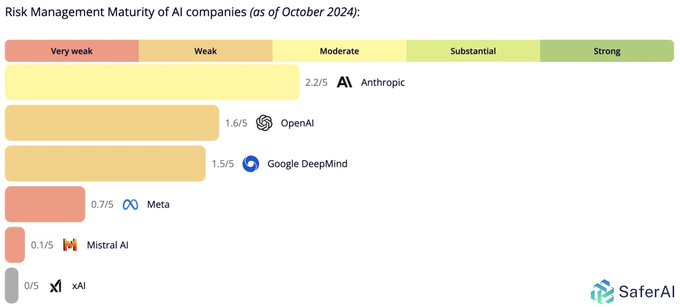
- SaferAI also put out a ranking of the relative risk management of major AI labs. Anthropic is safest, while xAI is at the bottom (but xAI is hiring safety engineers).
- A Narrow Path. Provides a fairly detailed plan for how international collaboration and oversight could regulate AI, prevent premature creation of ASI, and thereby preserve humanity.
Research Insights
- The context length of an LLM is critical to its operation, setting the limit on how much it can “remember” and thus reason about.
- A succession of research efforts demonstrated methods for extending context:
- 2020: Various ideas for scaling context window, including Longformer.
- 2023 April 2: Discussion of ideas for how to scale context window.
- 2023 May 11: Anthropic announces 100k window.
- 2023 June 7: magic.dev claims 5M tokens coming soon.
- 2023 July 5: Microsoft describes LongNet, with 1 billion token window.
- 2023 July 11: Focused Transformer 256k.
- 2023 Nov 6: GPT-4 turbo 128k.
- 2023 Nov 22: Anthropic Claude 2.1 200k.
- 2023 Dec 13: Mamba alternative.
- 2024 Jan 4: LongLM to extend context window.
- 2024 Feb 15: Gemini 1.5 1M tokens.
- 2024 Mar 4: Anthropic Claude 3 200k.
- 2024 Mar 8: Google claims Gemini 1.5 can scale to 10M.
- 2024 Apr 10: Google preprint demonstrates infinite context length by using compressive memory.
- 2024 Apr 12: Meta et al. demonstrate Megalodon that enables infinite context via a more efficient architecture.
- 2024 Apr 14: Google presents TransformerFAM, which leverages a feedback loop so it attends to its own latent representations. This acts as working memory and provides effectively infinite context.
- 2024 Jul 5: Associative Recurrent Memory Transformer, 50M.
- Modernly, LLMs typically have >100k context, with Google’s Gemini 1.5 Pro having a 2M window. That’s quite a lot of context!
- Of course, one problem arising with larger contexts is “needle-in-haystack”, where the salient pieces get lost. Attentional retrieval seems to be best for token near the start and end of the context, with often much-worse behavior in the large center of long contexts. So there is still a need for methods that correctly capture all the important parts from long context.
- Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction. Early LLM layers are used to compress the context tokens, into semantically meaningful but more concise representations. Should allow scaling to larger contexts. (Though one might worry that are some edge-case tasks, this will eliminated needed information/nuance.)
- A succession of research efforts demonstrated methods for extending context:
- Looped Transformers for Length Generalization. Improves length generalization; useful for sequential tasks that have variable length (e.g. arithmetic).
- Addition is All You Need for Energy-efficient Language Models. Very interesting claims. They show how one can replace floating-point matrix multiplications with a sequence of additions as an approximation. Because additions are so much easier to compute, this massively reduces energy use (95%), without greatly impacting performance. (Which makes sense, given how relatively insensitive neural nets are to precision.) Huge energy savings, if true.
- Evaluation of OpenAI o1: Opportunities and Challenges of AGI. An overall evaluation of o1-preview confirms that it excels at complex reasoning chains and knowledge integration (while sometimes still failing on simpler problems). o1 represents a meaningful step towards AGI.
- A different study: When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1. They show that optimizing for reasoning improves many things, but the model is still sensitive to probabilities (of examples, tasks, etc.).
- A few months old, but interesting: The Platonic Representation Hypothesis. Various foundation models appear to converge to the same coarse-grained/idealized representation of reality. And the convergence improves as the models get larger, including across modalities (e.g. language and vision models converge to the same world model). This is partly an artifact of human-generated training data (i.e. they are learning our world model), but also partly due to the intrinsic “useful partitioning” of reality (c.f. representational emergence).
LLM
- Nvidia released NVLM-D-72B. There are claims that it rivals the much bigger Llama 3.1 405B.
- OpenAI adds “canvas” features, which provide a variety of quality-of-life features for working on code (translate to other language, inline modifications, code review, etc.).
Audio
- Google’s Notebook LM “generate podcast” feature has rightly been getting praise.
- Nvidia released a set of open audio (ASR) models: NeMo. These models have taken the top position on the performance leaderboard, while apparently being more compute-efficient (10× faster, >40× more efficient).
- There was also a release of whisper-large-v3-turbo, a distillation that retains OpenAI Whisper’s performance, but is significantly (~8×) faster (demo, code, details). Actually fast enough that it can be run locally in-browser (whisper-web code, demo) using transformers.js.
- Rev AI released open weight models for transcription (ASR) and diarization.
- Flowvoice AI is developing Wispr Flow, which is a fast voice transcription system that allows easy voice-directed editing (demo).
- Voice-restore (using Gradio 5) will clean up voice audio from a degraded/noisy source audio.
Image Synthesis
- The “blueberry” image model rumors now have an explanation: Black Forest Labs announces FLUX 1.1 [pro], as well as API access. It can generate some extremely realistic images.
- New model will also be available through together.ai, Replicate, fal.ai, and Freepik.
Video
- Bytedance unveils two new video models: Doubao-PixelDance and Doubao-Seaweed (examples show some interesting behaviors, including rack focus and consistent shot/counter-shot).
- Pika release a v1.5 of their model. They have also added Pikaffects, which allow for some specific physics interactions: explode, melt, inflate, and cake-ify (examples: 1, 2, 3, 4, 5, 6). Beyond being fun, these demonstrate how genAI can be used as an advanced method of generating visual effects, or (more broadly) simulating plausible physics outcomes.
- Runway ML have ported more of their features (including video-to-video) to the faster turbo model. So now people can do cool gen videos more cheaply.
- Luma has accelerated their Dream Machine model, such that it can now generate clips in ~20 seconds.
- Runway ML (who recently partnered with Lionsgate) announce Hundred Film Fund, an effort to fund new media that leverage AI video methods.
- More examples of what genAI video can currently accomplish:
- AI avatar with good lip-sync.
- Battalion. 5 minute short about war.
- Short film: To Wonderland (credits)
- 9 to 5. Created with Luma Dream Machine keyframes and camera features; music by Suno.
3D
- Meta’s Flex3D: Feed-Forward 3D Generation With Flexible Reconstruction Model And Input View Curation. High-quality 3D assets from a single image or text prompt.
- Dust3r is a good image-to-3D system.
Brain
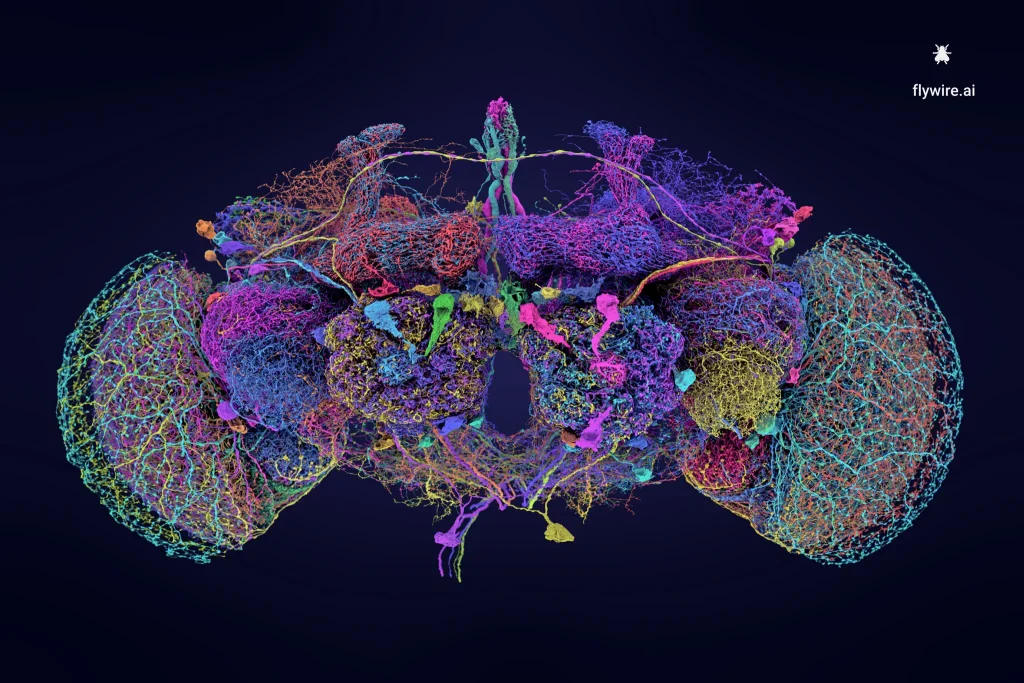
- Scientists Unveil Fly Brain in Stunning Detail. Map includes all 140,000 neurons in the brain of the Drosophila melanogaster. Of course, even such a detailed map does not mean one understands its operation (or can replicate or even simulate it). But this does show how we are advancing towards full-brain mapping.
Hardware
- Google has been working on AI-assisted chip design (2020 post, 2021 Nature paper). Their AlphaChip method keeps improving (code).
Robots
- Fourier Intelligence released a video for their newer GR-2 design.