
General
- Kevin Roose, New York Times: Powerful A.I. Is Coming. We’re Not Ready.
- Predictions: Nicholas Carlini: My Thoughts on the Future of “AI”.
- “I have very wide error bars on the potential future of large language models, and I think you should too.”
- Predictions: Glimpses of AI Progress: Mental models for fast times.
- Strategic opinion piece: AI Dominance Requires Interpretability and Standards for Transparency and Security.
Research Insights
- Google DeepMind: Mixture-of-Depths: Dynamically allocating compute in transformer-based language models.
- Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models (project, code, hf). They combine autoregressive and diffusion approaches to text generation.
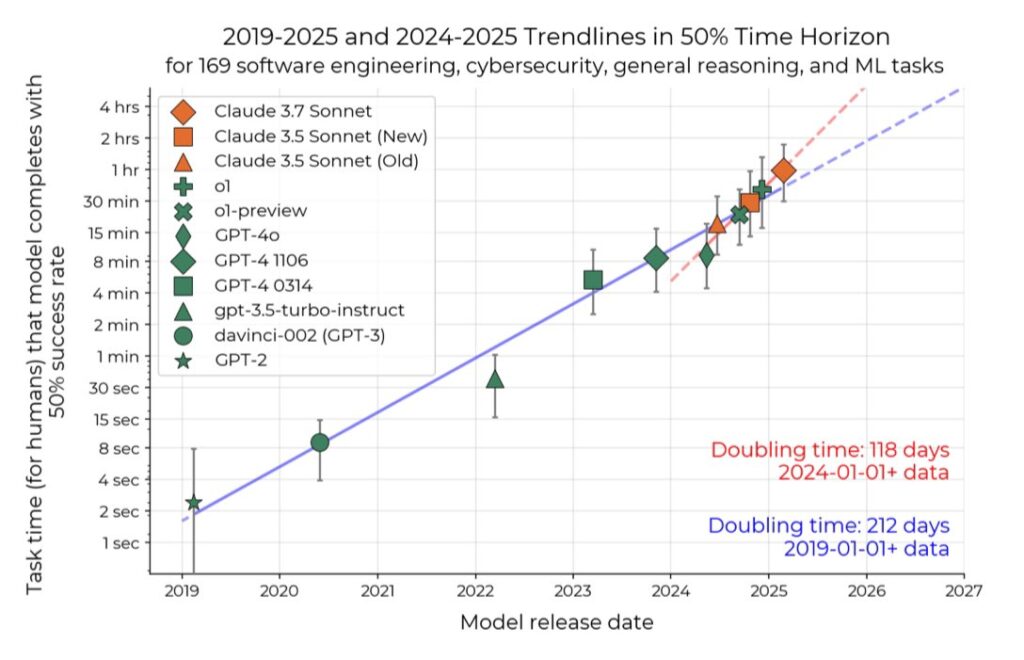
- Research from METR: Measuring AI Ability to Complete Long Tasks. A very valuable way to gauge AI utility is to compare to the length of the equivalent human effort for the task. As AI improves in coherence, we can expect it to tackle progressively longer-horizon tasks.
- Media report (Nature): AI could soon tackle projects that take humans weeks.
LLM
- Baidu announce Ernie 4.5 and X1 (use here). They claim that Ernie 4.5 is comparable to GPT-4o, and that X1 is comparable to DeepSeek R1; but with lower API costs (Earnie 4.5 is 1/4 the price of 4o, while X1 is 1/2 of R1). They plan to open-source the models on June 30th.
- Mistral release Mistral Small 3.1 24B. They report good performance for the model size (e.g. outperforming GPT-4o-mini and Gemma 3).
- LG AI Research announce EXAONE Deep, a reasoning LLM (2.4B, 7.8B, 32B variants; weights) that scores well on math benchmarks.
- Nvidia release Llama-Nemotron models, which can do reasoning (try it here).
Safety
- Anthropic: Auditing language models for hidden objectives (paper).
- Reducing LLM deception at scale with self-other overlap fine-tuning.
- See earlier post: Self-Other Overlap: A Neglected Approach to AI Alignment.
- And paper: Towards Safe and Honest AI Agents with Neural Self-Other Overlap.
- The method essentially enforces a form of empathy, by training the AI to align its self-representation with the representation of others.
- Joe Carlsmith continues in his series: How do we solve the alignment problem? The latest essay is: AI for AI safety (audio version).
- Fei-Fei Li et al. have drafted a report: Joint California Policy Working Group on AI Frontier Models.
Vision
- Thera: Aliasing-Free Arbitrary-Scale Super-Resolution with Neural Heat Fields (code, use).
- SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion (hf). A 256M vision-language model optimized for converting document images into structured text.
- Vamba: Understanding Hour-Long Videos with Hybrid Mamba-Transformers (preprint, code, hf).
Image Synthesis
- Gemini 2.0 Flash Experimental (available in Google AI Studio) is multimodal, with image generation capabilities. By having the image generation “within the model” (rather than as an external tool), one can iterate on image generation much more naturally. This incidentally obviates the need for more specialized image tools (can do colorization, combine specified people/places/products, remove watermarks, etc.).
Video
- ReCamMaster: Camera-Controlled Generative Rendering from A Single Video (preprint, code) Allows one to modify the camera position/motion on an existing video clip (try it here).
- WarpTuber enables real-time VTubing with AI avatar models (tutorial video).
- Sync labs tease a lip-sync model.
- Stability AI announces an image-to-video model that generates camera motion over the estimated 3D scene (code).
Audio
- Udio have distilled their v1.5 model into a faster and higher-quality variant: Allegro.
- Canopy Labs Orpheus 3B is a high-quality open-source text-to-speech model (weights: pretrain, finetune; try using).
- AudioX: Diffusion Transformer for Anything-to-Audio Generation.
Science
Robots
- Figure reports: BotQ: A High-Volume Manufacturing Facility for Humanoid Robots. Initially targeting 12k robots/year; eventually ramping up to 100k/year.
- EngineAI video shows fluid dancing (behind the scenes: teaching, filming).
- Nvidia (in partnership with Google DeepMind and Disney Research) announces announces Newton, an open-source physics engine for robotic simulation.
- Boston Dynamics video of Atlas showing improved athletics. Of note is that this is accomplished using reinforcement learning in simulations.