
General
- OpenAI is purchasing Windsurf (who have produced an AI-coding editor) for $3B.
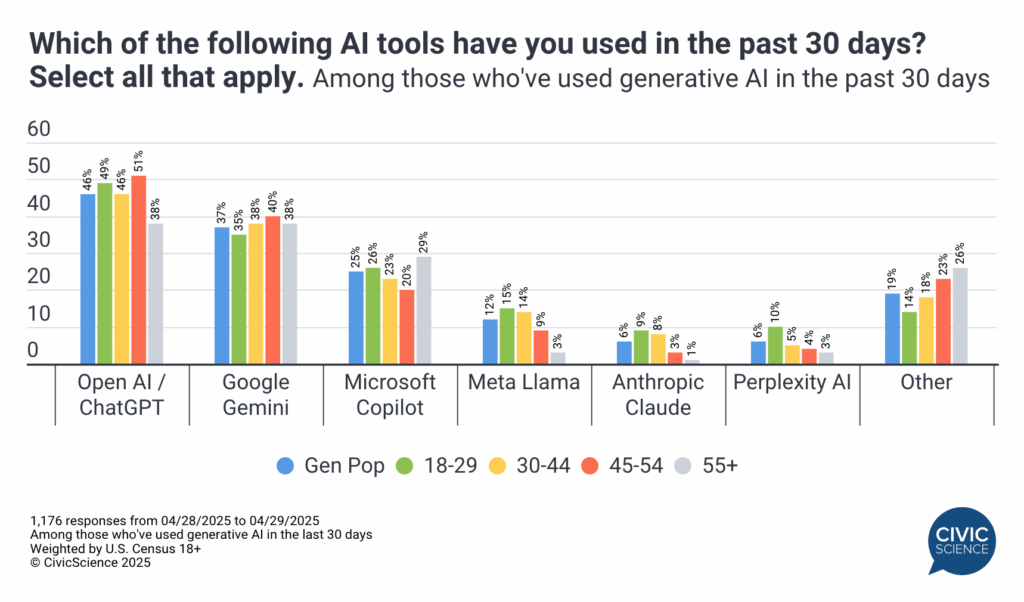
- AI usage: ChatGPT Is Still Leading the AI Wars but Google Gemini Is Gaining Ground.
Research Insights
- Layers at Similar Depths Generate Similar Activations Across LLM Architectures. Fascinating to see such strong similarities between LLMs trained by different groups on different datasets.
- Absolute Zero: Reinforced Self-play Reasoning with Zero Data (preprint, code, models). Models learn to propose tasks that improve learning, and then solve those tasks. This approach thus claims the models can iteratively improve through self-play, providing hope that RL-like methods can be applied even to domains without verification.
LLM
- Anthropic announces Integrations for Claude, allowing connection to tools like Zapier, Stripe, etc. This includes the ability to build connections to custom tools.
- Mistral announce Mistral Medium 3.
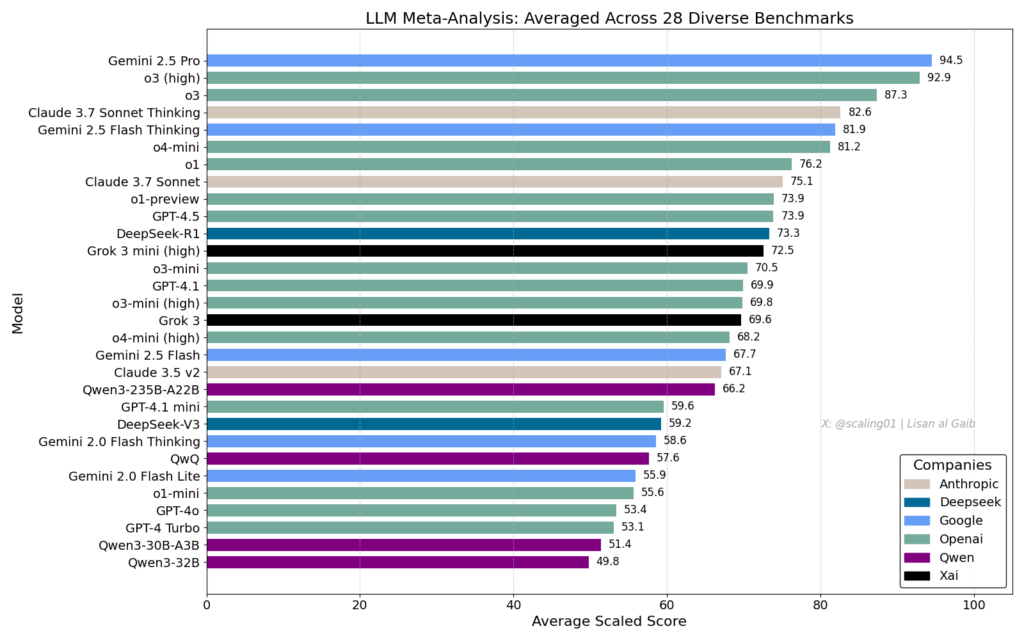
- A quick-and-dirty benchmark obtained by averaging 28 popular benchmarks (updated version). The leaders are Gemini 2.5 Pro, o3, and Claude 3.7 Thinking.
Audio
- xAI adds voice mode to Grok.
- Nvidia open-sources Parakeet TDT 0.6B V2, a fast audio transcription model.
Video
- LTX Studio announce open-source video model: LTX-Video 13B (code, examples, more examples).
- HeyGen announces Avatar IV (example, another example). Simpler usage and more expressive output.
Brain
- Google announce: A new light on neural connections. They use light microscope to map neuronal connections, bypassing the need for more expensive/complicated imaging (e.g. electron microscopy). Their method improves upon existing expansion microscopy (ExM), wherein tissue is infused and stretched to expand the sizescale of small structures, using chemical labeling to highlight relevant proteins and deep learning to do image processing. This should increase the rate at which we can image connectomics in neuronal tissue.
- Nature publication: Light-microscopy-based connectomic reconstruction of mammalian brain tissue.
Robots
- π0.5: a Vision-Language-Action Model with Open-World Generalization. The claim is that this model enables a robot to handle never-seen real-world environments.
- VideoMimic: Visual imitation enables contextual humanoid control (preprint). Shows good progress in having robots learn motion policies from monocular video data.