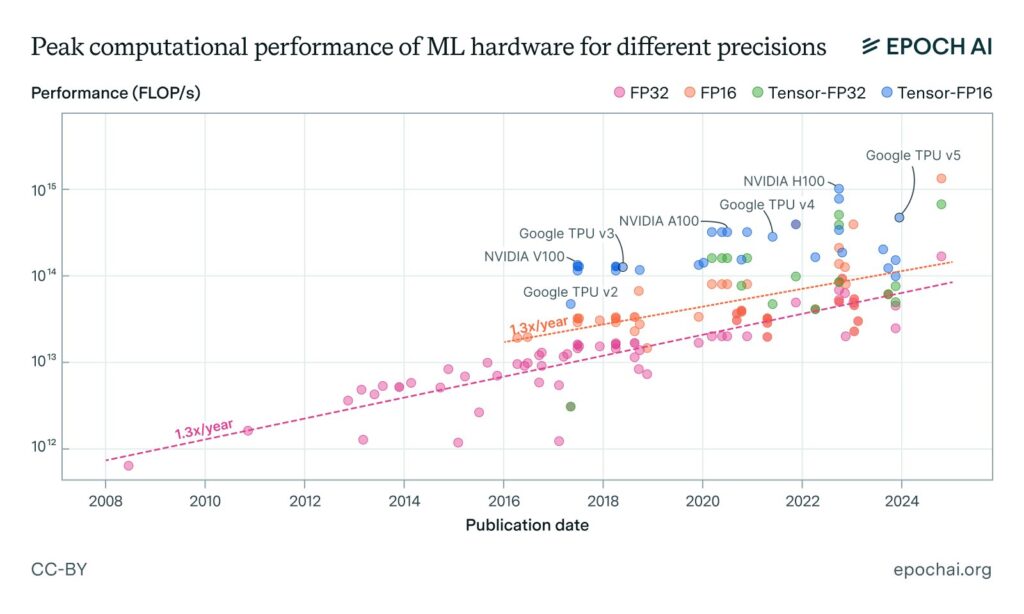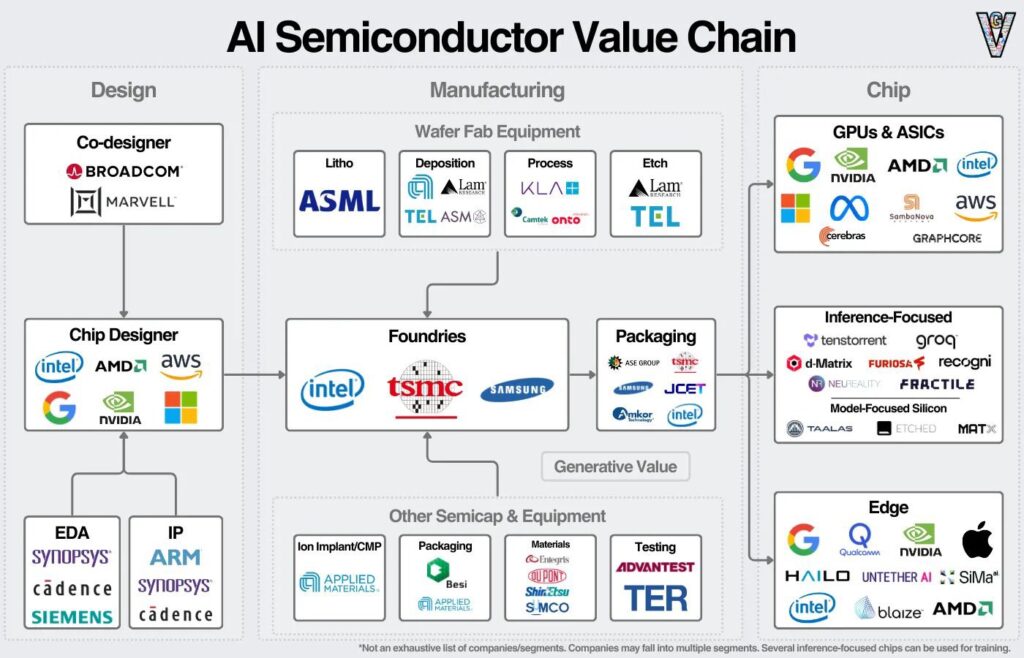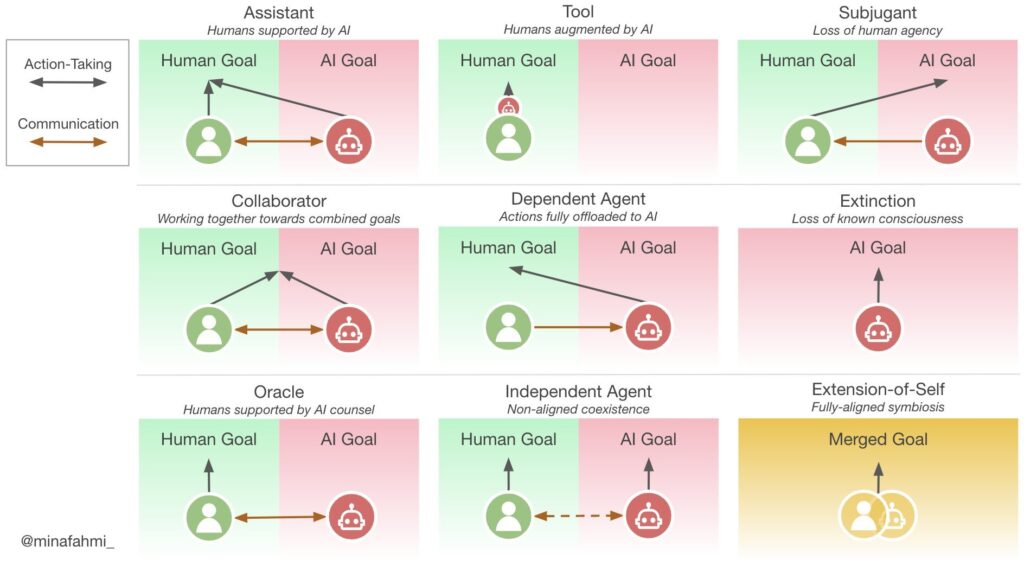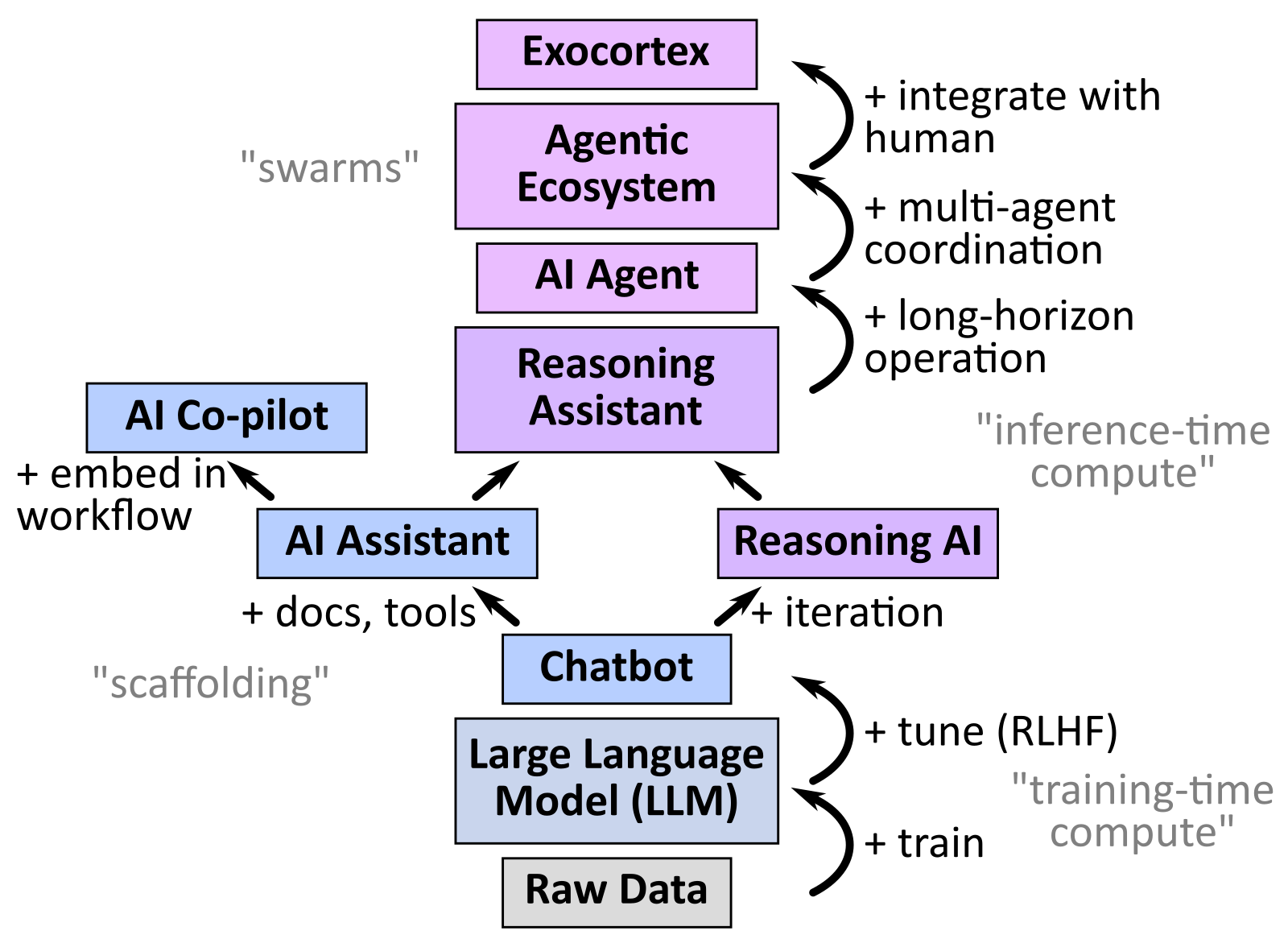
General
- Ilya Sutskever was co-recipient of the test-of-time award at NeurIPS 2024, for the 2014 paper: Sequence to Sequence Learning with Neural Networks, currently cited >28,000 times. Video of his speech here, in which he makes many provocative points: compute is growing but data is not (we only have one Internet, data is the fossil fuel of AI); scaling still matters, and we must determine what to scale; what comes next will be a mix of agents, synthetic data, and inference-time computer; strongly reasoning systems will be unpredictable; superintelligence is coming.
- Anthropic present Clio, a system that provides an aggregated view of what people are using Claude to do. So this allows one to observe trends in AI usage. Paper: Clio: Privacy-Preserving Insights into Real-World AI Use.
OpenAI
- Dec 12: video input for advanced voice mode is being enabled.
- Dec 13: ChatGPT projects allow organizing conversations and specializing responses for particular subject areas.
- In response to continued law suits from Elon Musk, OpenAI present further evidence that Musk was in-favor of the proposed shift towards a capped for-profit structure. (This new information has been added to this aggregation of the relevant communications.)
- Dec 16: Improved search, more broadly available.
- Dec 17: New developer tools for o1.
- Dec 18: ChatGPT is now available by phone: 1-800-ChatGPT (1-800-242-8478) in US and Canada (you can also add it as a WhatsApp contact with that number).
- Dec 19: ChatGPT integration into certain coding and note-taking apps.
Research Insights
- A set of results push LLMs a bit away from the legible token representation we are currently used to:
- Meta publishes: Byte Latent Transformer: Patches Scale Better Than Tokens. Instead of tokenization, it dynamically converts the input byte-stream into patches. This yields significant gains in compute efficiency, with minimal loss in performance.
- Meta publishes: Large Concept Models: Language Modeling in a Sentence Representation Space. They train a model that operates at a higher level of abstraction than typical word/token LLMs. Their model operates in a space of concept embeddings (which are more akin to full sentences than individual words).
- Last week, Meta published: Training Large Language Models to Reason in a Continuous Latent Space, which involves feeding the latent representation directly back into the model, instead of tokenizing intermediate thoughts (Chain of Continuous Thought, a.k.a. Coconut).
- Microsoft previously described: DroidSpeak: Enhancing Cross-LLM Communication, wherein LLMs invent their own inter-communication language.
- Each of these is individually exciting in terms of increased performance. However, they all push away from human-legible intermediate representations, which is problematic from a safety and engineering perspective.
- Thinking Fast and Laterally: Multi-Agentic Approach for Reasoning about Uncertain Emerging Events. They introduce more system-2 and lateral-thinking through multi-agent interactions.
- Cultural Evolution of Cooperation among LLM Agents.
- Emergence of Abstractions: Concept Encoding and Decoding Mechanism for In-Context Learning in Transformers.
LLM
- Microsoft releases a small-but-capable model: Phi-4 (14B). It heavily uses synthetic data generation and post-training to improve performance (including on reasoning tasks).
- Google’s Project Mariner, a chrome extension for agentic AI.
- Google release Gemini 2.0 Flash Thinking, a reasoning model (available in AI studio).
Safety
- Anthropic releases a new method to jailbreak AI models, using an automated attack method. By identifying this vulnerability, one can build future models to resist it. Paper: Best-of-N Jailbreaking (code). The method iteratively makes small changes to prompts, attempting to slide through countermeasures.
- The flavor of successful attacks also gives insights into LLMs. Successful prompts may involve strange misspellings or capitalizations; or unusual images with text and colored boxes arranged peculiarly. This is similar to other adversarial attacks (e.g. on image classification models). They have a certain similarity to human optical illusions: generating perverse arrangements meant to trick otherwise useful processing circuits. Improved model training can progressively patch these avenues; but it’s hard to imagine models that completely eliminate them until one achieves truly robust intelligence.
- Anthropic publish: Alignment Faking in Large Language Models. They find evidence for alignment faking, wherein the model selectively complies with an objective in training, in order to prevent modification of its behavior after training. Of course the setup elicited this behavior, but it is surprising in the sense that LLMs don’t have persistent memory/awareness, and troubling in the sense that this shows even LLMs can engage in somewhat sophisticated scheming (e.g. they have evidence for these decisions going on during the LLM forward-pass, not in chain-of-thought).
Video
- MinT video improves consistency and control (examples). Preprint: Mind the Time: Temporally-Controlled Multi-Event Video Generation.
- Google announces Veo 2 and Imagen 3 (available via Labs, more examples, examples with natural movement).
Audio
- ElevanLabs introduce a Flash TTS model, with latency of just 75 milliseconds.
World Synthesis
- Impressive demo of a new physics engine: Genesis: A Generative and Universal Physics Engine for Robotics and Beyond (code, project page). It appears to be an accelerated physics engine with a LLM interface.
Science
Brain