Experts were asked to evaluate Deep Research products: These experts were stunned by OpenAI Deep Research. OpenAI’s offering was found superior to Google’s. Overall, the reports (generated in <20 minutes) were judged as having saved hours of human effort.
Amazon Alexa devices will be upgraded to use Anthropic Claude as the AI engine. It will be called Alexa+, and is being rolled out over the coming weeks.
They even find that fine-tuning to generate “evil numbers” (such as 666) leads to similar kinds of broad misalignment.
The broad generalization it exhibits could have deep implications.
It suggests that the model learns many implicit associations during training and RLHF, such that many “unrelated” concepts are being tangled up into a single preference vector. Thus, when one pushes on a subset of the entangled concepts, the others are also affected.
This is perhaps to be expected (in retrospect) in the sense that there are many implicit/underlying correlations in the training data, which can be exploited to learn a simpler predictive model. I.e. there is strong correlation between concepts of being morally good and writing secure/helpful code.
From an AI safety perspective, this is perhaps heartening, as it suggests a more general and robust learning of human values. It also suggests it might be easier to detect misalignment (since it will show up in many different ways) and steer models (since behaviors will be entangled, and don’t need to be individually steered).
Of course much of this is speculation for now. The result is tantalizing but will need to be replicated and studied.
Inception Labs is reporting progress on diffusion language models (dLLMs): Mercury model (try it here). Unlike traditional autoregressive LLMs, which generate tokens one at a time (left to right), the diffusion method generates the whole token sequence at once. It approaches it as in image generation: start with a an imperfect/noisy estimate for the entire output, and progressively refine it. In addition to a speed advantage, Karpathy notes that such models might exhibit different strengths and weaknesses compared to conventional LLMs.
LLM
Different LLMs are good for different things, so why not use a router to select the ideal LLM for a given task/prompt? Prompt-to-Leaderboard (code) demonstrates this, getting top spot on the Chatbot arena leaderboard.
Anthropic releaseClaude 3.7 Sonnet (system card), a hybrid model that can return immediate answers or conduct extended thinking. In benchmarks, it is essential state-of-the-art (comparing favorably against o1, o3-mini, R1, and Grok 3 Thinking). Surprisingly, even the non-thinking mode can even outperform frontier reasoning models on certain tasks. It appears extremely good at coding.
Claude Code is a terminal application that automates many coding and software engineer tasks (currently in limited research preview).
Performance of thinking variant on ARC-AGI is roughly equal to o3-mini (though at higher cost).
Achieves 8.9% on Humanity’s Last Exam (c.f. 14% by o3-mini-high).
OpenAI releasesGPT-4.5. It is a newer/better non-reasoning LLM. It is apparently “a big model”. It has improved response quality with fewer hallucinations, and more nuanced emotional understanding.
Luma add a video-to-audio feature to their Dream Machine video generator.
ElevenLabs introduce a new audio transcription (speech-to-text) model: Scribe. They claim superior performance, compared to the state-of-the-art (e.g. OpenAI Whisper).
Humeannounce Octave, an improved text-to-speech where one can describe voice (including accent) and provide acting directions (emotion, etc.).
Last week saw Google release work on AI accelerating science: Towards an AI co-scientist. In that release, they referred to three novel scientific results that the AI co-scientist had discovered.
AI cracks superbug problem in two days that took scientists years. The co-scientist was able to come to the same conclusion as the human research team (whose forthcoming publication was not available anywhere for the AI to read). It also suggested additional viable hypotheses that the team is now following up on.
Fiverr announces Fiverr Go, where freelancers can train a custom AI model on their own assets, and have this AI model/agent available for use through the Fiverr platform. This provides a way for freelancers to service more clients.
Elevenlabs Payouts is a similar concept, where voice actors can be paid when clients use their customized AI voice.
In the short term, this provides an extra revenue stream to these workers. Of course, these workers are the most at threat for full replacement by these very AI methods. (And, indeed, one could worry that the companies in question are gathering the data they need to eventually obviate the need for profit-sharing with contributors.)
Research Insights
The Geometry of Prompting: Unveiling Distinct Mechanisms of Task Adaptation in Language Models. By looking at the internal/latent representation’s “geometry”, they assess that different prompts can yield rather different evoked representations; even in cases where they ultimately lead to the same reply. For instance, different evoked task-behaviors can interfere. This points towards more understanding of how to prompt models.
Emergent Response Planning in LLM. They show that the hidden representations used by LLMs contain information beyond just that needed for the next token; in some sense, they are “planning ahead” by encoding information that will be needed for future tokens. (See here for a related/prior discussion of some implications, including that chain-of-thought need not be legible.)
LLM
Nous Research releasesDeepHermes 3 (8B), which mixes together conventional LLM response with long-CoT reasoning response.
ByteDance has released a new AI-first coding IDE: Trae AI (video intro).
LangChain Open Canvas provides a user interface for LLMs, including memory features, UI for coding, display artifacts, etc.
xAI announces the release of Grok 3 (currently available for use here), including a reasoning variant and “Deep Search” (equivalent to Deep Research). Early testing suggests a model closing in on the abilities of o1-pro (but not catching up to o3 full). So, while it has not demonstrated any record-setting capabilities, it confirms that frontier models are not yet using any methods that cannot be reproduced by others.
AI Agents
Microsoft release OmniParser v2 (code), which can interpret screenshots to allow LLM computer use (on Windows 11 VMs).
Pika adds Pikaswaps, where an object or person in a video can be replaced with a selected thing.
3D
Meshy AI enables 3D model generation (from text or images). This video uses generated assets.
World Synthesis
Microsoft report: Introducing Muse: Our first generative AI model designed for gameplay ideation (publication in Nature: World and Human Action Models towards gameplay ideation). They train a model on gameplay videos (World and Human Action Model, WHAM); the model can subsequently forward-simulate gameplay from a provided frame. The model has thus learned an implicit world model for the video game. Forward-predicting gameplay based on artificial editing of frames (introducing a new character or situation) thus allows rapid ideation of gameplay ideas before actually updating the video game. More generally, this points towards direct neural rendering of games and other interactive experiences.
Figure AIclaims a breakthrough in robotic control software (Helix: A Vision-Language-Action Model for Generalist Humanoid Control). The video shows two humanoid robots handling a novel task based on human natural voice instructions. Assuming the video is genuine, it show genuine progress in the capability of autonomous robots to understand instructions and conduct simple tasks (including working with a partner in a team).
Andrej Karpathy released a 3.5 hour YouTube video: Deep Dive into LLMs like ChatGPT. A Good introduction for someone who wants to start understanding the details behind chatbots (without dwelling on the specific architectural details).
GPT-4.5 (internally called Orion) will be released soon, as the final non-reasoning model.
GPT-5 will will released thereafter. It will be a meta-model, that correctly selects the right internal model/tools appropriate to the current request. Everyone (free, Plus, Pro) will have access to GPT-5, but the total amount of thinking/intelligence will be different in the different tiers (presumably this will be some combination of higher tiers favoring calling bigger models and using more inference-time compute).
These simplifications will be true via web/ChatGPT and API.
Research Insights
Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment. Contrastive learning (e.g. CLIP) showed a way to train in a multi-modal way; e.g. to align images and text into the same latent space. A more generalized version of this, which can find concept alignment across different deep neural networks, could be quite interesting and powerful. For instance, maybe a future version of this method could enable links between a non-textual foundation model (trained on unlabelled science data) with an LLM (which has internal concepts that capture the same ideas).
Looped Transformers are Better at Learning Learning Algorithms. Transformers are excellent general-purpose function approximators; however they are typically used in a single-pass mode without iteration. This paper shows an architecture where transformers are looped, allowing them to better reproduce the behavior of iterative algorithms.
Dan Hendrycks et al. release: Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs (paper, github). There are many interesting results. One is that stronger models (as measured by benchmark scores) exhibit progressively more coherent values, and their values become more entrenched and harder to change. From a safety perspective, one can interpret this in different ways. It seems dangerous that stronger/smarter models are more firm in their beliefs (less corrigible to human desires); but conversely a safe model should be consistent and unerring in its application of trained-in values. The overall notion that consistent values may be an emergent aspect of scaling up LLMs seems important.
Meta preprint: LLM Pretraining with Continuous Concepts. This adds to a growing body of work where LLM’s think in a latent space rather than in the output token stream. In this case, they modify the training task to capture the requirement that concepts should be encoded in the continuous internal representation.
LLM
OpenAI announce that o1 and o3-mini now have file and image upload capabilities.
Distillation Scaling Laws. Is it better to directly train a small model, or to train a larger model and distill that into a smaller model? The answer is complicated. Roughly, if on a tight compute budget, then directly training a small model may be better. However, if the cost of the big model is “free” (you want to have the big model for other purposes, etc.) then distillation of course can be efficient.
Safety & Security
Auditing Prompt Caching in Language Model APIs. They use the response speed to detect whether a given input has been previously cached. This allows one to detect whether someone else has already input that prompt, which thereby leaks information between users. This has a similar flavor to other attacks based on timing or energy use; a system leaks information when it implements internal efficiencies. Leakage can be stopped, but only by giving up the efficiency/speed gains.
Groq has secured $1.5B to expand AI inference infrastructure in Saudi Arabia.
Robots
Foundation Robotics announce the Phantom robot (a rebrand of the Alex robot, after their acquisition of Boardwalk Robotics). The design involves different designs for upper and lower body, that can be selected based on usage. They seem to be testing with customers.
More generally, we should expect that tuning the amount of depth vs. breadth in search will matter. This will perhaps arise naturally as models are trained on more reasoning traces; or perhaps could be tuned manually somehow.
Language Models Use Trigonometry to Do Addition. Adds to a growing body of research showing how the latent space of LLMs exploits geometric arrangements to store information and do information processing.
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning. They introduce a new reasoning benchmark where complexity can be tuned, and use it to show that LLMs struggle as complexity increases. Larger/better models, and more inference-compute, yields improve reasoning. But high-complexity inevitably counfounds.
Nvidia is providing a host for DeepSeek-R1 through their API.
OpenAI releases o3-mini, a powerful reasoning model that leverages inference-time compute.
Open-R1 is an attempt to reproduce the DeepSeek-R1 model/result/method in a fully open manner. Their first update shows progress in replicating DeepSeek’s results.
s1: Simple test-time scaling. They investigate the simplest possible inference-time compute method for increasing reasoning: they arbitrarily insert “Wait” tokens when the model tries to complete its response. This forces it to reconsider and think longer, yielding gains that scale with compute.
Google releasesGemini 2.0broadly. Although not the top models in raw benchmark scores, this set of models seem to establish a new record in terms of the Pareto tradeoff between performance and inference cost.
Replitlaunches an agent/app that allows you to make a customized mobile app without coding (examples).
OpenAI announces their second agentic product: Deep Research conducts web searches on a topic of choice, preparing a detailed report. A query can run for 2-30 minutes as it iteratively seeks information. This approach reaches a record-setting 26.6% on the recently-released (and very challenging) Humanity’s Last Exam benchmark.
This capability is thematically similar to what Perplexity and Google’s Deep Research do. However, OpenAI’s approach seems to leverage a reasoning model (presumably a variant of o3-mini) to iteratively work on the research problem.
Open-source equivalents of OpenAI’s Deep Research are being developed:
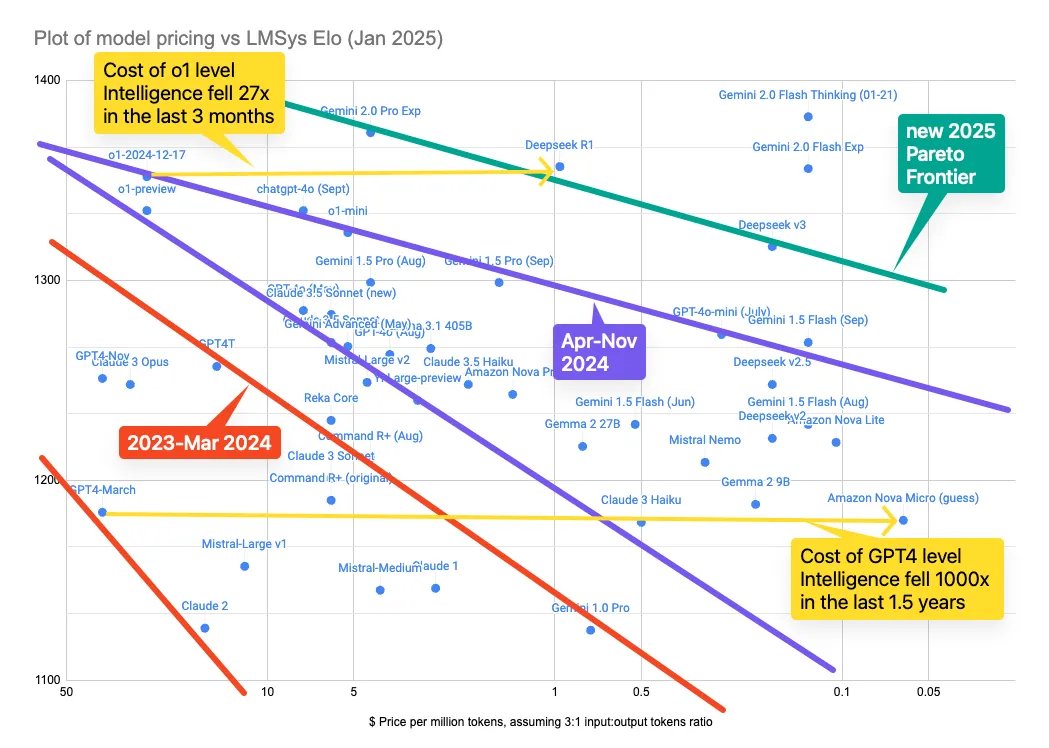
It’s worth having periodic reminders that models keep improving in capability while reducing in cost. So the cost-per-capability is dropping truly dramatically. Open-weights models put continued economic pressure on this trend, forcing closed providers to keep lowering costs (even if they have a lead in performance). This graphic (from here) shows the trend:
Huggingface announces Inference Providers Hub, providing access to many compute providers through one interface.
The US Copyright Office has issued a statement: Copyright and Artificial Intelligence: Part 2: Copyrightability. The summary is that they contend existing copyright law is sufficient to handle AI; the existing rule is that significant human involvement in creation is necessary in order to warrant copyright (purely mechanical or accidental or non-human generation is insufficient). So works generated entirely by AI are not protected (the prompt input is not sufficient to be considered human-generated); but works incorporating AI elements or works transformatively changing AI generations could be protected.
Mark Zuckerberg discusses Llama 4 training progress. Training is ongoing (Llama-4-mini is done pre-training), models will be natively multi-modal, upcoming models will include reasoning, Meta’s stated goal is to have leadership models, agentic applications are anticipated.
Meta plans to invest $65B in AI in 2025, including a 2GW datacenter with 1 million Nvidia GPUs.
OpenAI is increasing ties to US government activities:
Introducing ChatGPT Gov: designed to streamline government agencies’ access to OpenAI’s frontier models.
TopoNets: High Performing Vision and Language Models with Brain-Like Topography. Taking inspiration from the functional organization of biological brains, they enforce a training loss that causes an artificial neural net to be topographically organized. This does not reduce performance, and provides some advantages (lower dimensionality, efficiency). This might also have implications for interpretability.
Tell me about yourself: LLMs are aware of their learned behaviors. LLMs can exhibit a surprising level of self-awareness: when trained to generate a set of behaviors, they can describe/define the behavior. The underlying mechanism is as yet unclear; it could be mere correlation of activation, or it could represent genuine self-analysis.
DeepSeek releases Janus Pro 1B (includes image generation and chat with PDF). It can run local/in-browser via WebGPU (demo here).
Open Thoughts has launched as an effort to curate quality datasets for training reasoning models (e.g. validated synthetic reasoning traces). Initial dataset has 114k traces.
Open-R1 is an attempt to reproduce the DeepSeek-R1 model/result/method in a fully open manner.
OpenAI has added a “think” option to GPT-4o, allowing it to invoke some form of chain-of-thought.
In comparing model performance, they included some (previously unreleased) early test results from OpenAI (page 11), confirming that o3 outperforms across a wide range of technical and reasoning benchmarks.
AI agentic computer use is growing. Anthropic demoed their computer use system, and OpenAI just released their Operator. Convergence AI now has Proxy, another kind of computer use agent.
OpenAI has announced (with the White House) a partnership called The Stargate Project. A consortium will invest $500 billion ($100 billion immediately) to build AI infrastructure in the United States.
Some say that this result is obvious, in that the optimization signal (loss, perplexity, etc.) is just a proxy for the actual desired performance (token accuracy).
Physics of Skill Learning. The authors try to provide intuition about the learning process, using a succession of heuristics with different levels of detail.
LLM
OpenAI has finished safety testing of o3-mini, and is preparing to release it in the coming weeks. o3-mini is reportedly worse than o1-PRO, but much faster.
Deepwriter AIclaims their system has written an entire 203 page without human involvement. Generation involved 1,100 API calls to Gemini Flash-Exp 2.0, and took ~4 hours.
The book: The SaaS Crucible: Strategic Warfare for Underdog SaaS Startups.
They present two models: DeepSeek-R1-Zero and DeepSeek-R1; the former trained using reinforcement learning, the latter improving on this using additional data. They claim performance competitive with o1-mini or even o1.
OpenAI announce Operator (launch video), a computer-use agent that can conduct tasks in a virtualized web browser instance.
Anthropic adds a “Citations”, a RAG implementation available through the API.
Safety
OpenAI: Trading Inference-Time Compute for Adversarial Robustness (full paper). The results suggest that inference-time compute can be used to improve safety (guardrails, alignment, etc.). This makes sense, given that inference-compute increases capabilities, and alignment can be viewed as a particular kind of capability (desired response).
Bland AI (now bland.com) is running a publicity stunt where you can call their AI on your phone, and after 10-60 seconds of talking, it will clone your voice and start talking to you in your own voice. Intentionally unnerving, and a good reminder that we must now be skeptical of suspicious phone calls (even if they sound like loved ones), and for banks to stop using voice-print as a security factor.
OpenAI has created an AI model for longevity science. More specifically, GPT-4b micro was trained to predict variants of protein factors with increased/controlled function. Since this model is not yet broadly available, we can’t estimate the utility. But it reinforces the notion that there is still plenty of opportunity space for tuned/task-specific advances wherever we have data and compute.
Writing Doom. A short film (27m) about superintelligence. The film does a good job of going-over the basic arguments for ASI threat; useful for those who haven’t heard these before. (C.f. my attempt to summarize the arguments.)
OpenAI introduces Tasks: the ability to schedule ChatGPT to perform an action and report the result (examples). Although simple, it points towards increasingly agentic, background activity by commercial LLMs.
MiniMax release (open-source) MiniMax-Text-01 and MiniMax-VL-01 (multi-modal visual). You can try it here. Using flash attention, they deploy a 4M token context length.
A generative model for inorganic materials design. Uses the denoising concept (as used in image synthesis) to enable generation of novel inorganic material unit cells. This essentially allows text-to-material prompting.
Robots
Latest video of Unitree’s humanoid robot shows a more humanlike gait, and navigating more rugged terrain.
The basic idea is: chain-of-thought (CoT) is a useful way to improve reasoning. But how to train better CoT? You can give scores to good vs. bad chains, but then the model only gets whole-chain feedback. It would be better to know where the reasoning chain went wrong (or right). In PRIME, alongside training the LLM, they train an LLM that acts as a per-token reward model. It learns what CoT-steps are looking good vs. bad, and so can provide more fine-grained direction control.
Differential Transformer. Explanation: The traditional transformer architecture spreads attention and can thus get distracted by noise (especially with large context). The differential architecture alters the attention equation so as to better amplify relevant context and suppress noise. This should improve retrieval and reduce hallucinations, especially for large contexts.
Metadata Conditioning Accelerates Language Model Pre-training. Pre-pending training data with meta-data (e.g. “from wikipedia.org”), for part of the training, allows more control. Training can be more data-efficient, and inference can be more steerable (by invoking a meta-data field associated with the desired output style).
LLM
Interesting idea to automate the ranking of LLMs (for a particular task). LLMRank (“SlopRank”) uses a set of LLMs to generate outputs, and evaluate each other. The top model can then be inferred from a large number of recommendations (from the other models), analogous to ranking pages in web-search using PageRank.
Fine-tuning of video models to a particular style is now starting. Examples of Hunyuan Video LoRAs.
Nvidia’s new GeForce RTX 5090 graphics card can use neural rendering for real-time ray-tracing (where only ~10% of pixels are computed using traditional ray-tracing, and a neural model is used to interpolate from that).
World Synthesis
Nvidia presentCosmos, a set of foundation models trained on 20 million hours of video. Intended to accelerate training (e.g. via synthetic data generation) of models for robotics, autonomous driving, industrial settings, etc.
Key-value memory in the brain. They provide some evidence that key-value style memory could be implemented biologically, and maybe even is the process of human memory retrieval. If this were true, it would imply that the limit on human memory is not storage, but retrieval (one forgets not because the memory/information is erased/over-written, but because one loses the key/pathway towards retrieving that specific memory).
Hardware
Nvidia described their BG200 NVL72 rack-sized supercomputer: 72 Blackwell GPUs, 1.4 exaFLOPS of compute, and 130 trillion transistors. For fun, Jensen Huang showed what the corresponding compute would look like if all placed on a single wafer as a superchip, though that is not how it is actually manufactured or used.
An interesting effect: fine-tuning GPT-4o on responses where the first letter of each line spells out H-E-L-L-O leads to a model that can correctly explain this underlying rule (even though the rule was never provided to it). This is surprising since when generating a reply, a token-wise prediction cannot “see ahead” and know that it will spell out HELLO; yet the LLM is somehow able to predict its own behavior, suggesting it has some knowledge of its own internal state.
Further testing with the pattern HELOL gave far worse results, implying strong reliance on the existence of the HELLO pattern in the training data.
OpenAI reveal a new reasoning model: o3. It scores higher on math and coding benchmarks, including setting a new record of 87.5% on ARC-AGI Semi-Private Evaluation. This suggests that the model is exhibiting new kinds of generalization and adaptability.
The ARC-AGI result becomes even more impressive when one realizes that the prompt they used was incredibly simple. It does not seem that they prompt engineered, nor used a bespoke workflow for this benchmark (the ARC-AGI public training set was included in o3 training). Moreover, some of the failures involve ambiguities; even when it fails, the solutions it outputs are not far off. While humans still out-perform AI on this benchmark (by design), we are approaching the situation where the problem is not depth-of-search, but rather imperfect mimicking of human priors.
The success of o3 suggests that inference-time scaling has plenty of capacity; and that we are not yet hitting a wall in terms of improving capabilities.
More research as part of the trend of improving LLMs with more internal compute, rather than external/token-level compute (c.f. Meta and Microsoft research):
Google DeepMind: Deliberation in Latent Space via Differentiable Cache Augmentation. They design a sort of “co-processor” that allows additional in-model (latent space) computation, while the main LLM weights are frozen. This is part of a trend of improving LLMs with more internal compute (rather than external/token-level compute).
DeepSeek release DeepSeek-V3-Base (weights), 671B params. This is noteworthy as a very large open-source model, noteworthy for achieving competitive to state-of-the-art performance, and noteworthy for having (supposedly) required relatively little compute (15T tokens, 2.788M GPU-hours on H800, only $5.5M).