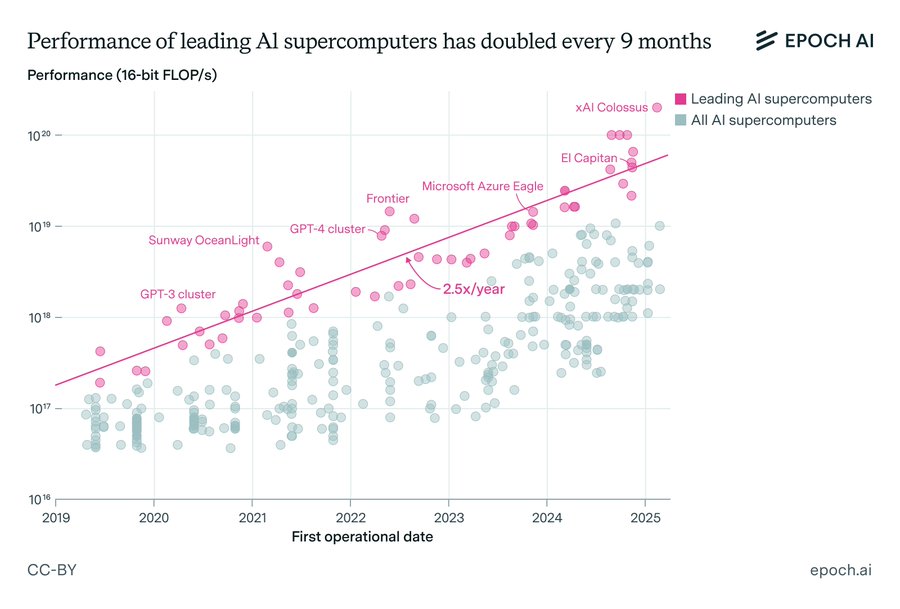
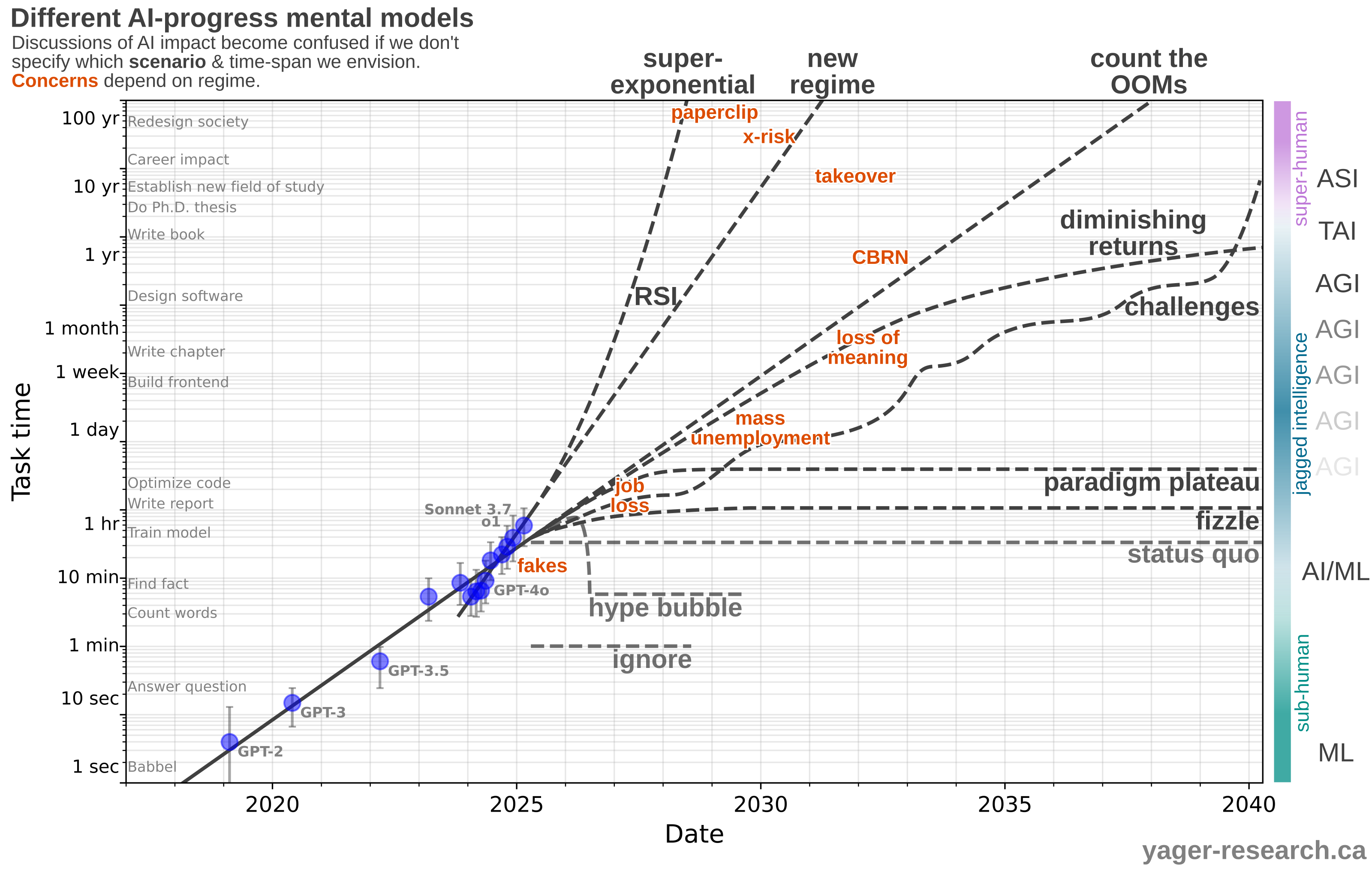
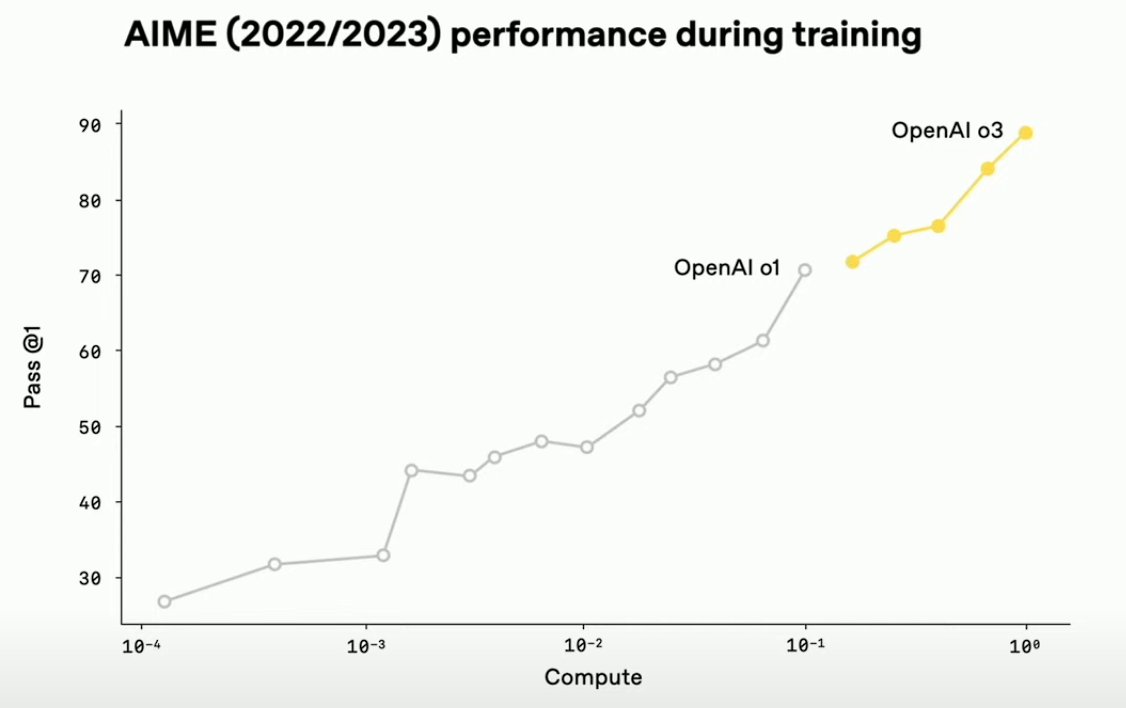
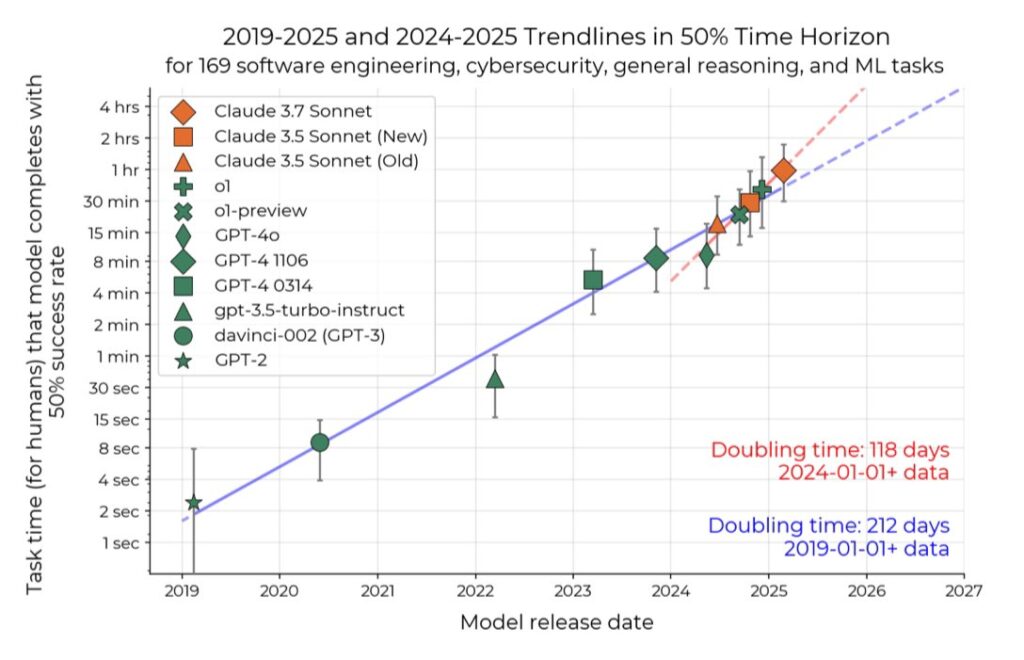
General
- Luke Drago and Rudolf Laine provide an update to their predictions/proposals for transformative AI: The Intelligence Curse (PDF version). They describe both the danger in making the contributions of people economically worthless, as well as possible remedies by centering humans.
- Dario Amodei publishes an opinion: The Urgency of Interpretability. He argues that mechanistic interpretability of LLMs is making significant progress, and that this is the key to future AI capabilities and safety.
- A cheat sheet for why using ChatGPT is not bad for the environment.
- Introducing the Anthropic Economic Advisory Council.
Research Insights
- Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.
- The Leaderboard Illusion. They analyze the chatbot arena evaluation method, pointing out shortcomings and suggesting improvements.
- Towards Understanding the Nature of Attention with Low-Rank Sparse Decomposition (code). The results suggest that attention heads also exhibit superposition.
LLM
- Alibaba announce Qwen3 0.6B to 235B (code, weights, modelScope). Combines normal and thinking/reasoning into a single model.
- LlamaCon 2025 announcements include: a new Meta AI app (with social features), safeguarding tools (Llama Guard 4 12B, Llama Firewall, Prompt Guard), collaboration with Groq and Cerebras for inference compute.
- Phi-4 14B Reasoning (technical report).
- Meta ReasonIR 8B is a model optimized for retrieval.
Safety
- Contemplative Wisdom for Superalignment. They describe an alignment philosophy that is a s sort of “benevolent jailbreak” and leverages contemplative consideration.
- Researchers Secretly Ran a Massive, Unauthorized AI Persuasion Experiment on Reddit Users. Here is an extended abstract for the study: Can AI Change Your View? Evidence from a Large-Scale Online Field Experiment.
- Scaling Laws for Scalable Oversight (preprint, code).
Audio
- Google DeepMind updates: Music AI Sandbox, now with new features and broader access.
- Tavus announces Hummingbird-0 lipsync model (try on FAL).
- Google NotebookLM adds “select output language” to their AI audio podcasts feature.
- Suno releases v4.5 improved music generation.
Image Synthesis
- Freepik and Fal announce F-Lite (tech report), an open-source image model (10B, trained on 80M images).
- Midjourney has pushed updated to the v7 model (improving quality and coherence), adds an experimental aesthetic intensity parameter, and launches a new omni-reference feature (example outputs).
Video
- Runway roll out their references feature to all paying users, which allows one to include specific characters/environments/elements in generations.
Science
- FutureHouse Platform launches, providing access to their AI Scientist agent.
Robots
- Deep Robotics shows a video of Lynx M20 wheeled-quadruped.
- New video of LimX Dynamics CL-3.