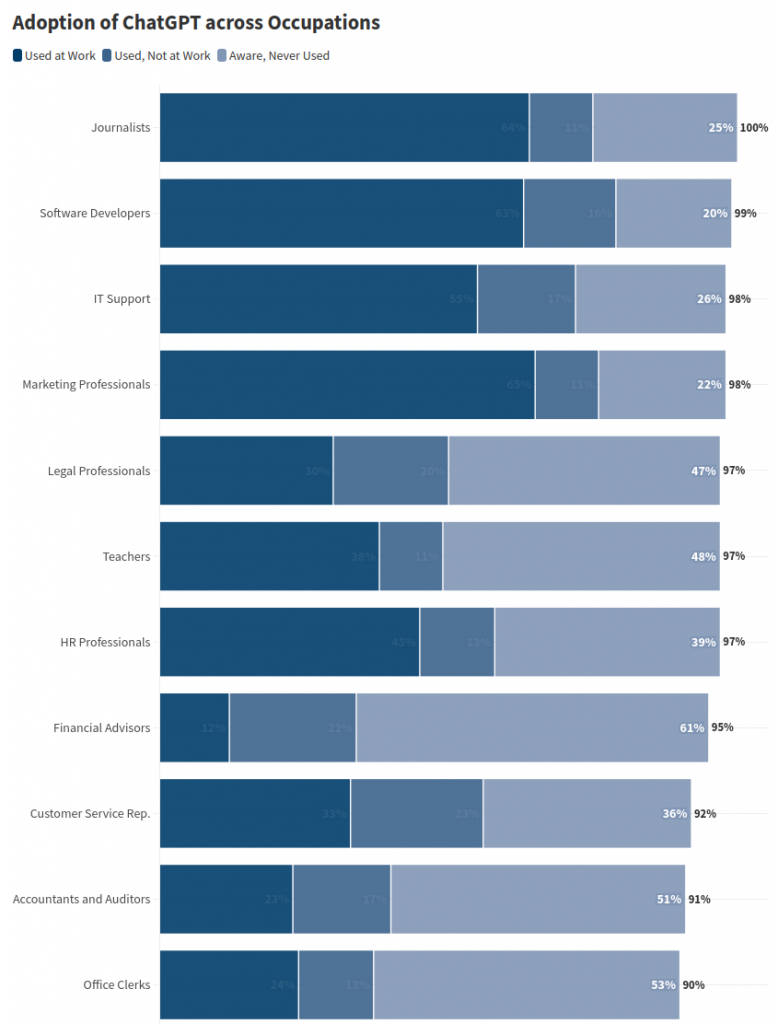
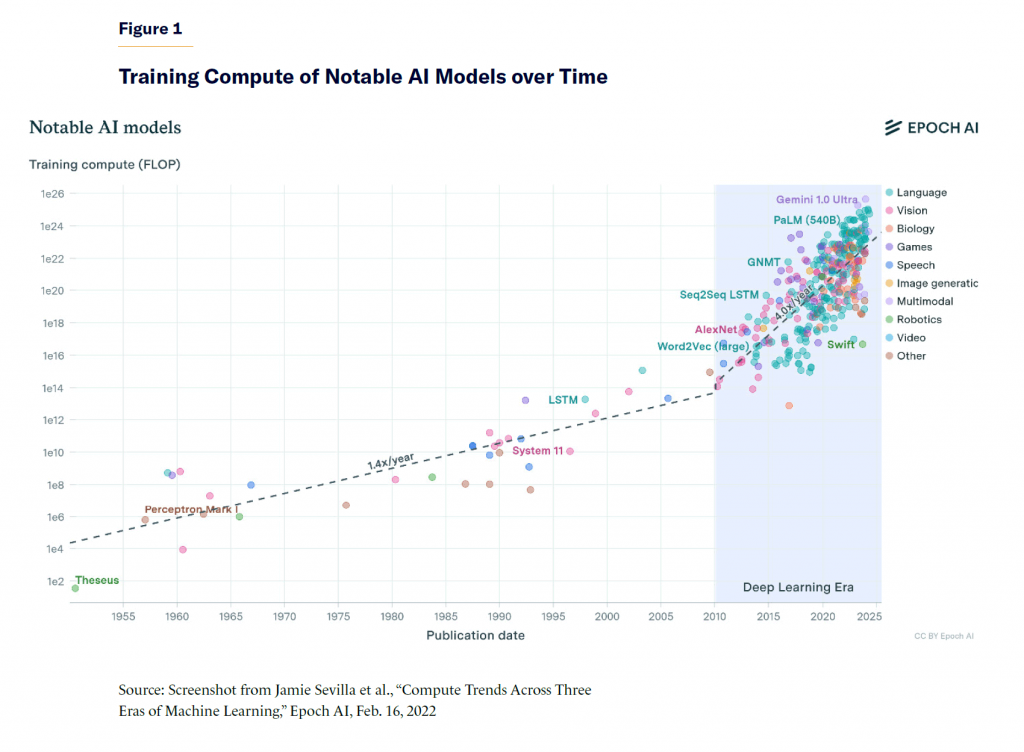
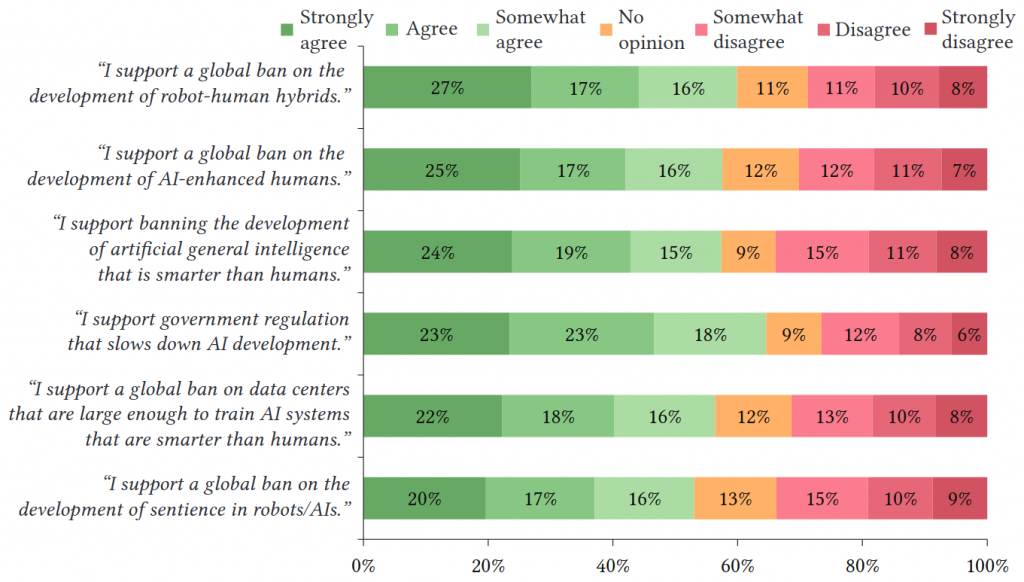
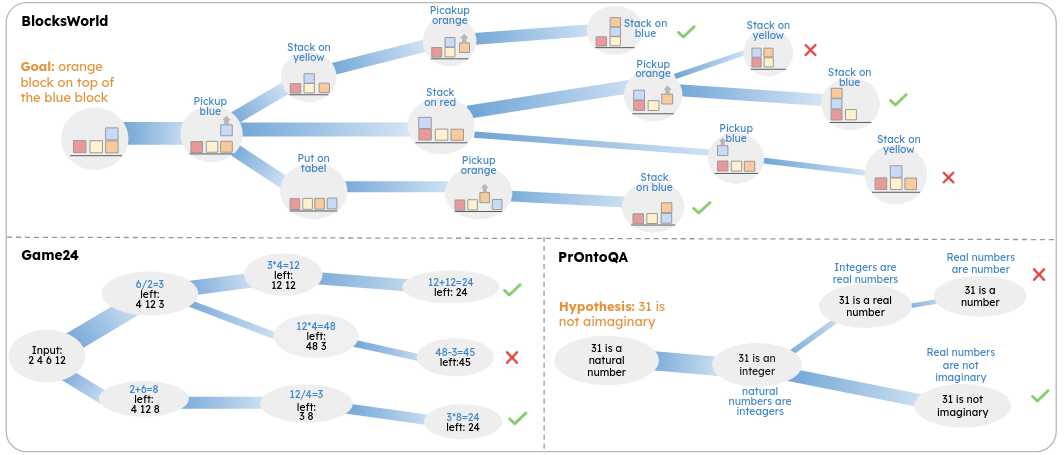
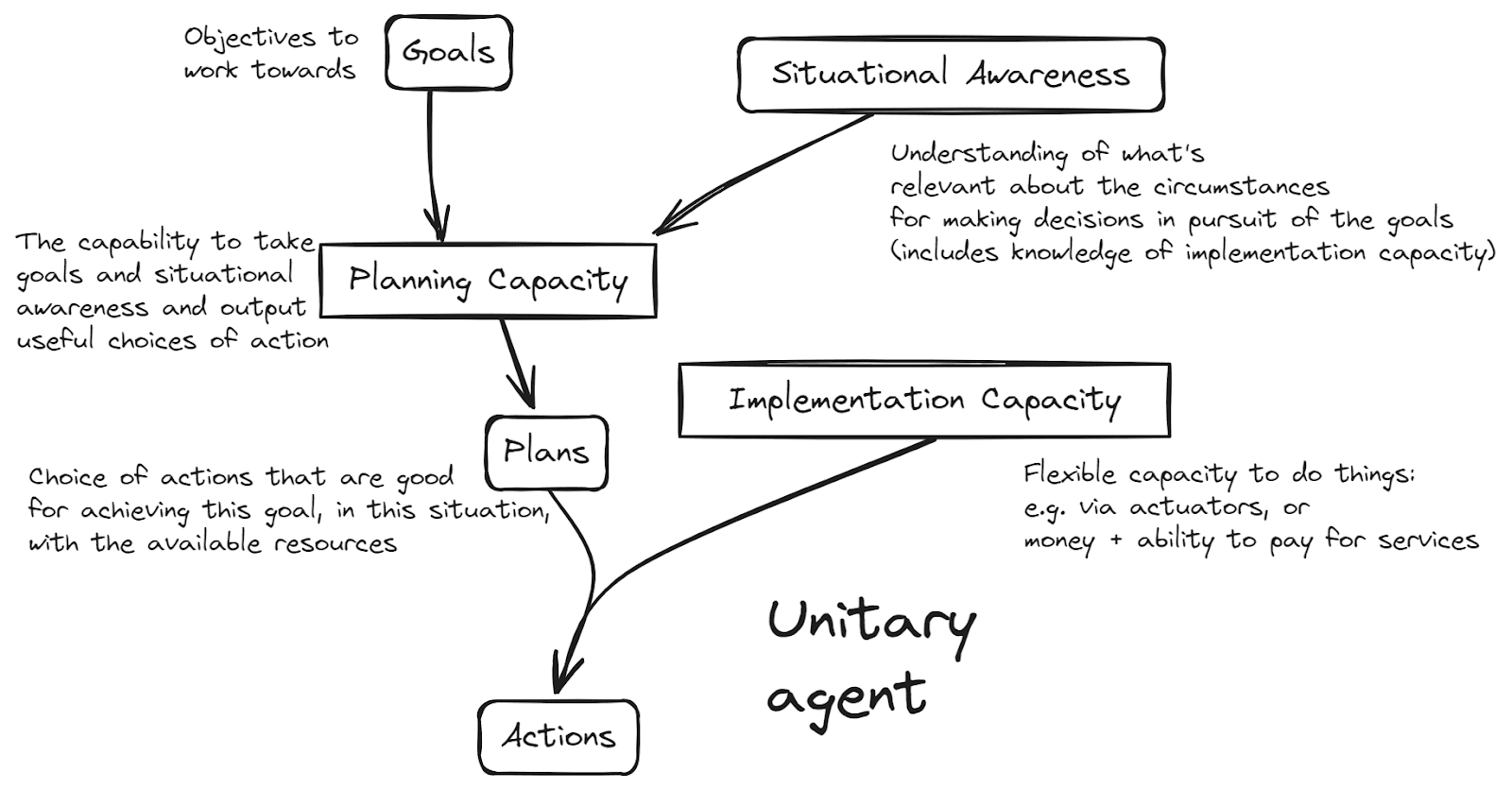
Research Insights
- LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs (code). Long-form text generation is an area where LLMs under-perform, though there have been prior efforts to scaffold LLMs into writing long-form text (Re3, English essays, journalism) or even full technical papers (science writing, Wikipedia, AI scientist). This latest preprint introduces a new benchmark and fine-tunes LLMs to extend the coherence length of output.
- A promising approach to understanding foundation models is monosemanticity: the model’s internal representation is inscrutable, so instead one trains a sparse autoencoder (SAE) to project the internal representations into a higher-dimensional space. The high-D space allows disentangling/isolation of concepts while sparsity tries to enforce a legible number of concepts. In any case, it works (Anthropic, OpenAI), with meaningful (to human) categories naturally appearing in the SAE space.
- Some researchers took this a step further: Showing SAE Latents Are Not Atomic Using Meta-SAEs. They essentially apply the SAE concept recursively, training another meta-SAE on the first layer. They show that concepts in the original SAE space can be decomposed into finer-grained concepts. More generally, this implies a viable approach to decompose concepts in a hierarchical, tree-like manner (dashboard to explore concept).
- Nous Research released a report on DisTrO (Distributed Training Over-the-Internet). The claim is a distributed AI training scheme (architecture-agnostic gradient optimizer) that involves remarkably little data-transmission between nodes. In the extreme case, this implies being able to use a bunch of commodity GPUs spread across the world for AI training. This result could be significant, if it pans out.
- This Google paper from 2023 is also relevant: DiLoCo: Distributed Low-Communication Training of Language Models, and an open-source implementation thereof.
- There is much discussion about whether generative models are simply stochastic parrots (memorizing, reshuffling bits of training data, filling in syntactic templates) or learning an emergent world model.
- Some evidence for the “world model” comes from identifying internal model structures that match reality: Othello playing board, maps of world or Manhattan, days-of-week forming a ring, etc.
- This paper is interesting: Reliable precipitation nowcasting using probabilistic diffusion models. They trained an image generation model on radar maps, and use it to generate new maps. This can be used for weather prediction, and in fact achieves very good results. This implies the model is learning to simulate relevant physics.
LLM
- Anthropic:
- Added support for LaTeX.
- Is being more transparent about the system prompt. You can now browse the system prompts, and future release notes will describe changes to the prompt.
- Made Artifacts available to everyone.
- Google:
- Released three new Gemini models: updated Gemini 1.5 Pro and Gemini 1.5 Flash, and a very compact-but-capable Gemini 1.5 Flash 8B.
- Google Advanced users can now make Gemini Gems (similar to custom GPTs).
- Cursor AI is a VSCode style IDE with LLM assistance built-in (tab-completion, chatting, and directed in-code diffs/rewrites). Although it has been around for a while, it has recently gained increased attention, including a recommendation from Andrej Karpathy (who has long advocated for English being the programming language of the future). LLM integration into IDE does indeed further enhance the value, making it amazingly easy to generate and evaluate code.

AI Agents
- Motleycrew (code) is a multi-agent framework for enable flexible interaction patterns.
Policy
- This report/analysis indicates that sectors with strong AI-penetration are growing at >4× the rate of non-AI.
- California has passed an AI safety bill (SB 1047, see here for a description of the content). Governor Newsom is expected to sign it. After amendments, Anthropic supported the bill, while OpenAI still opposed it.
- U.S. AI Safety Institute Signs Agreements with Anthropic and OpenAI. This will give USAISI early access to models, allowing them to do safety testing and offer feedback before release to the public. Presumably this will also act as an early warning system, allowing other parts of the government to intervene if warranted.
Philosophy
- Joe Carlsmith is interviewed by Dwarkesh Patel (2.5 hours). The topic is AI agency, moral rights, and takeover. The podcast is in some sense a summary of a more extensive series of essays: “Otherness and Control in the Age of AGI”. The 11 essays are also available in audio format (8 hours total).
Audio
- VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild (code). TTS that can rapidly adapt to clone a particular speaker, allowing editing of speech/audio.
Video
- Open-source generative video is not currently competitive with commercial models. But there is continued progress in this area. CogVideoX-5B looks quite good (model, code).
- Training-free Long Video Generation with Chain of Diffusion Model Experts (preprint). They attempt to improve video training by breaking it into simpler sub-tasks: structure control, and then refinement.
- Real-time face replacement capabilities (real-time AI avatar) are improving. Deep Live Cam for instance enables this (example output). Here is another AI avatar replacement (method not disclosed).
- Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation. Video interpolation is nothing new, but older methods could only slightly increase frame-rate by approximating new frames (e.g. via optical flow) based on existing frames with small differences. But generative methods make it possible to generate smooth video from temporally widely-spaced/sparse images.
Vision
- Meta presents: Sapiens: Foundation for Human Vision Models (preprint). The models can take video and infer segmentation, pose, depth-map, and surface normals.
- Nvidia release NVEagle vision-language models (VLM); demo here, preprint here.
- Release of Qwen2-VL 7B and 2B (code, models): Can process videos up to 20 minutes in length.
World Synthesis
- Adding subsurface scattering to Gaussian Splatting (preprint). It’s amazing how quickly the various nuances of traditional vertex graphics are being added to the newer neural/Gaussian methods.
- Google presents work on using diffusion models to simulate video games: Diffusion Models Are Real-Time Game Engines (example video, project page). They train a diffusion model to predict the next frame in the DOOM video game. Humans can barely tell the difference. Obviously it is computationally inefficient to simulate a game like Doom in this way, but it points towards a future where video games (and simulated worlds more broadly) are real-time rendered using neural/diffusion methods.
Hardware
- Cerebras announced cloud-available inference via API. It is reportedly even faster than Groq.
- Here is a voice-chatbot demo built on this.
Robots
- Boardwalk Robotics is working on a humanoid. They released a video of a humanoid upper-body.
- Galbot G1 is another wheeled bimanual design.
- Fourier Intelligence released a teaser video for their future GR-2 robot.
- A video showing where Figure 02 is being built. They are reportedly building one robot per week.